Azure Data Architecture Guide - Blog #1: Introduction
I’m proud to introduce you to the recent Azure Data Architecture Guide! This guide acts as a menu or syllabus for data professionals to select their data services and technologies.
Find the blog posts in this series here:
- Azure Data Architecture Guide – Blog #1: Introduction - This one
- Azure Data Architecture Guide – Blog #2: On-demand big data analytics
- Azure Data Architecture Guide – Blog #3: Advanced analytics and deep learning
- Azure Data Architecture Guide – Blog #4: Hybrid data architecture
- Azure Data Architecture Guide – Blog #5: Clickstream analysis
- Azure Data Architecture Guide – Blog #6: Business intelligence
What service should you use, why, and when would you use it? Sometimes you need to know all your options and what to use when, so that you can make the right decisions. This content set currently weighs in at 36 articles and features more capability matrices (comparison charts) than I have ever seen in one place. It was developed by AzureCAT and patterns & practices, in conjunction with Solliance, for the Azure Architecture Center.
About the guide
The Azure Data Architecture Guide (ADAG) presents a structured approach for designing data-centric solutions on Microsoft Azure. It is based on proven practices derived from our AzureCAT (Customer Advisory Team) customer engagements, and it leverages the expertise from countless Microsoft and partner advisors. You can read ADAG and explore the different data architectural designs on the Azure Architecture Center:
We’d like your feedback! Please leave a comment on this blog post with any feedback you might have, including high-level ideas about the structure or approach of the content, anything you think might be missing, as well as any specific details you’ve found.
The guide is broken down into two categories: Traditional RDBMS workloads and Big data solutions.
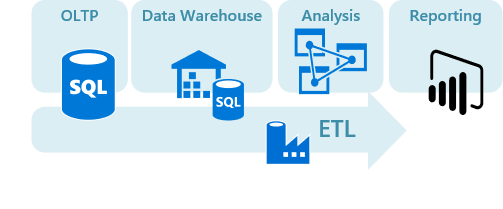
Figure 1. Traditional RDMS workloads covered in ADAG.
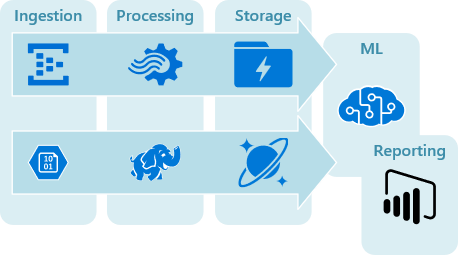
Figure 2. Big data and related Azure technologies covered in ADAG.
ADAG contains different types of articles:
- Concepts. These overview articles introduce the main concepts you need to understand when working with each type of data.
- Scenarios. Each of these articles represents a set of data scenarios, including a discussion of the relevant Azure services and the appropriate architecture for the scenario.
- Technology choices. These pages provide detailed comparisons of the various data technologies that are available on Azure, including open source options. Within each category, we describe the key selection criteria and a capability matrix, to help you choose the right technology for your scenario.
Finally, we include a series of Cross-cutting concerns that apply to many different data-architecture scenarios.
Table of contents
Traditional RDBMS workloads
- Traditional relational database solutions
- Online transaction processing (OLTP)
- Data warehousing and data marts
- Online analytical processing (OLAP)
- Extract, transform, and load (ETL)
Big data architectures
Concepts:
- Big data architectures - Overview
- Batch processing
- Real time processing
- Machine learning at scale
- Non-relational data and NoSQL
Scenarios:
- Advanced analytics
- Data lakes
- Processing free-form text for search
- Interactive data exploration
- Natural language processing
- Time series solutions
- Working with CSV and JSON files for data solutions
Technology choices:
- Choosing an analytical data store in Azure
- Choosing a data analytics technology in Azure
- Choosing a batch processing technology in Azure
- Choosing a Microsoft cognitive services technology
- Choosing a big data storage technology in Azure
- Choosing a machine learning technology in Azure
- Choosing a natural language processing technology in Azure
- Choosing a data pipeline orchestration technology in Azure
- Choosing a real-time message ingestion technology in Azure
- Choosing a search data store in Azure
- Choosing a stream processing technology in Azure
Cross-cutting concerns:
- Transferring data to and from Azure
- Extending on-premises data solutions to the cloud
- Securing data solutions
Key Credits
There are many unsung heroes in large content sets like this, so we'll include some of our top contributions. From Solliance, Zoiner Tejada (author profile on Amazon) and Joel Hulen wrote the bulk of the content, taking the quantity of visual diagrams and capability-matrix comparison tables to historic new levels (if there were records, they are now broken)!
From our AzureCAT patterns & practice team, our cohorts included Christopher Bennage (vision for this content), Masashi Narumoto (information architecture and flow), and Mike Wasson (information architecture and flow, updates implementations, structural refinements, and editorial). Our key Microsoft collaborators included Graeme Malcolm (a senior content developer on our online courses in data technologies) and James Serra (a Microsoft cloud and data solution architect). Our contributing editors from Resources Online include RoAnn Corbisier and Nanette Ray.
Our AzureCAT reviewers contributed their customer engagement expertise. They include Emil Velinov, Dimitri Furman, Abhisek Banerjee, Christian Martinez, Jeff King, KR Kandavel, Mike Weiner, Sanjay Mishra, Ben Humphrey, Matthew Winter, John Hoang, Rangarajan Srirangam, and Audrey Colle. We also received a review from our cloud solution architect, Brig Lamoreaux, and from Microsoft team members working on SQL and Azure data services, including Jos de Bruijin, Xiaochen Wu, Sunil Agarwal, Jovan Popovic, Alain Dormehl, Veljko Vasic, Chris Brooks, and Matthew Roche.
Special thanks go out to our customer advisory board members, for the great reviews and feedback they’ve given! Our key members include Tom Kerkhove (Codit), and in alphabetical order, Adwait Ullal (Travelport), Alejandro Leguizamo (Altius), Alejandro Miguel (Honeywell), Andreas Trinks (Daimler), Bas Pruijn (Alten), Bhaskar Dasari (Capgemini), Dan Neff (Adobe), Ilkka Peltonen (OP), Jamin Mace (eLynx), Karl Ots (Kompozure), Marcin Krawczyk (IT Magination), Melissa Coates (Blue Granite), Michael Jonsson (Avanade), Patrick Gallucci, Perry Thompson (Accenture), Reuben Cabrera (GMO), Sean Forgatch (Talavant), Stephen Giles (Dimensional Strategies), Steve Catmull (Health Catalyst), and Whit Waldo (Ebiquity).
We sincerely hope that ADAG provides a clear path for you to architect your data solution on Azure!
![]()
Azure CAT Guidance
"Hands-on solutions, with our heads in the Cloud!"