Cloud computing guide for researchers – Research data management and collaboration
Research is a collaborative endeavour, but it's not always easy to share data, workflows and software with others in the lab, research group, or around the world. Cloud computing makes this much easier, by being able to host data, workbooks, and computing together in one place. You can share as much data as you like, and it's as easy as using Azure Storage Explorer, Python, or command line tools, as explained in this video, and this detailed walkthrough on Github. Jupyter notebooks are one example of how collaborative open science is developing, with Azure providing executable Notebooks-as-a-Service for free. Azure provides the ideal platform for creating services that make research data and outputs easily available. Data Commons and reproducible research platforms are ideally suited for implementation on the cloud, by bringing data, compute, and tools together for researchers to create results, collaborate, analyse data, share, archive and preserve their outputs.
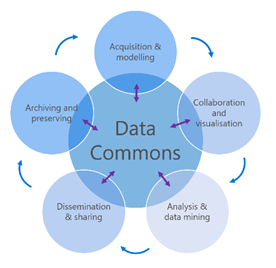
Making Research Data Work
Making data available requires a combination of scalable infrastructure and tools that are researcher-friendly. Organisations such as the National Biodiversity Network and Ag-Analytics are using Microsoft Azure to provide seamless access to research data and tools. The ability to easily design and deliver end-to-end research data and collaboration tools means that teams can focus on creating the best experience for their users.
A wide range of cloud technologies makes this easier than ever for research data management, including:
- Azure storage, with a tiered model for optimising cost and efficiencies:
- Azure blob storage for scalable object storage of unstructured data. It includes blob object-level tiering Azure for optimizing costs without moving your data:
- Hot storage tier frequently accessed data
- Cool storage tier with same, fast access times as hot storage, at much reduced storage cost
- Archive storage for low cost, durable, highly available, secure cloud storage for rarely accessed data with flexible latency requirements (on the order of hours).
- Azure Files. Simple, distributed, cross-platform replacement to network file share in the cloud
- StorSimple for automated, hybrid on-premise and Azure storage
- Azure blob storage for scalable object storage of unstructured data. It includes blob object-level tiering Azure for optimizing costs without moving your data:
- Azure Data Lake Store for unstructured, semi-structuers and structured data, with no limit on size. Azure Data Lake Store is secured, massively scalable and built in accordance with the open HDFS standard, allowing you to run massively parallel analytics.
For structured relational databases, Azure offers Database-as-a-Service to allow you to easily deploy and manage systems without having to worry about the underlying infrastructure. This includes support for the most popular database systems, as well as new cloud-scale services.
- Azure database Postgres and MySQL. This allows you to spend more time building your research management services by providing automatic database patching, automatic backups, built-in monitoring, security and more.
- CosmosDB globally distributed, multi-model database service. It is flexible, with native MongoDB API support, support Gremlin graph APIs, and Spark connector or doing real-time machine learning.
- Azure Tables, flexible NoSQL key-value store for semi-structured datasets
Jupyter Notebooks made easy – and free!
Jupyter notebooks are one example of how collaborative open science is developing, with Microsoft providing Notebooks-as-a-Service for free. These Jupyter notebooks on Azure, available as a service, fully executable, and shareable. These are a great way to do science in a reproducible way. You can start from scratch or upload your existing notebooks to Azure at https://notebooks.azure.com 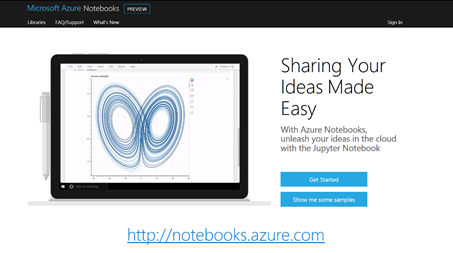
These can be used to share your science, such as the LIGO Open Science Centre. They have made data and analysis pipeline available using Azure Notebooks, so that researchers can reproduce the results of the gravitational waves discovery – see https://losc.ligo.org/tutorials/ You can also build more complex Jpyter notebook setups combining free Azure Notebooks, Jupyter hub on Azure virtual machines (including GPUs) and on-premise servers. See the UK Faculty Connection blog for more details.
Research-as-a-Service
Microsoft Azure means that you can not only host data, but build researcher-centric services to make this data work for users. For example, Nicola Bonzanni at ENPICOM uses Azure to build Conbind, phylogenetic fingerprinting Research-as-a-Service for genomics researcher worldwide. Read more about it here.
Parker MacCready at the University of Washington has used Azure to complement his university's Linux HPC cluster, by building a cloud system to manage his regional climate simulation output data, and make it available to other as part of the LiveOcean project. Jan Newton, principal oceanographer at the Applied Physics Laboratory and co-director of the Washington Ocean Acidification Project (WOAP), believes it may change how the public sees climate change and ocean chemistry. She explains, "Data portals and models like LiveOcean can really make a bridge [of understanding] because even if people don't understand the chemistry, they'll look at the color-coding and see how this changes with location and season." You can read more about it here. 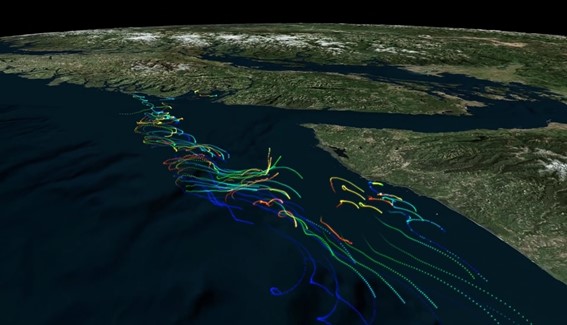
Learn more
There are more general Azure getting started videos at https://azure.microsoft.com/en-us/get-started/ and a full set of Azure for Research self-pace walkthroughs at https://aka.ms/learncloud
We are publishing more in this blog series on more advanced topics for researchers to take advantage of Azure. So stay posted in our cloud computing guide for researchers.
Need access to Microsoft Azure?
There are several ways you can get access to Microsoft Azure for your research. Your university may already make Azure available to you, so first port of call is to speak to your research computing department. There are also other ways for you to start experimenting with the cloud:
There are several free Azure services for you to also explore: