Cloud computing guide for researchers – Parameter sweep computation made easy with Azure Batch
When you need to go from running on your laptop or desktop computer, to run dozens, or hundreds, of computations, then cloud computing can literally be like a time machine. Azure Batch makes it easy to create many machines to simultaneously run your jobs, so you can get your results in few hours or days, rather than waiting weeks or months.
Accelerating science from 80 days to just two
Dr Vasilis Glennis and Professsor Chris Kilsby at the University of Newcastle, UK, have developed a highly-detailed flood model for cities. The City Catchment Analysis Tool (CityCAT) system combines topographic maps, building, and green space data, with a sewer and surface water model to be able to simulate how water accumulates when there is intense rainfall. Flood risk mapping and analysis with CityCAT allows: Identification of vulnerable areas; Identification of sources of runoff; Identifying opportunities for alleviation, and; Design and testing of schemes The initial high-resolution modelling of their home town showed good results, which they could check with data from a major flood that took place on 28th June 2012. The team's modelling is used in the European RAMSES research project, that aims to measure the impact of climate change, analysing the cost and benefits of different adaptation measures in cities. Knowing how flood risk changes under climate change, and can be reduced with interventions, is a key part of the project. The problem was that the researchers had to move from simulating one city, to 571 across Europe.
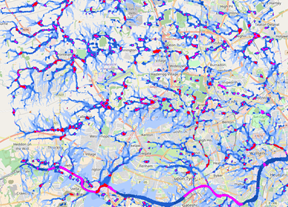
Flood map for Newcastle under 150mm/hour rainfall scenario
Going from one to n machines is easy
The CityCat model can take two days to run on a single powerful computer. The team was worried that they would not be able to finish all their simulation in time, as they had to run nine different rainfall scenarios for each of the 571 cities across Europe. They turned to Microsoft Azure to setup a parameter sweep process, using the Azure Batch system. Azure Batch is a service that handles the provisioning, scheduling, and scaling of a pool of (virtual) machines, to complete a suite of jobs. The steps we used for the setup of the parameter sweep jobs were simple:
- Uploading the data and the application to Azure storage;
- Creating jobs and tasks for the pool of VMs; and
- Calling a script for each task, with a set of parameters to configure and run the application.
Once a task is completed the results are uploaded to the cloud and the VMs terminated after the completion of the jobs.
To perform the simulations for the 571 cities, a pool of 40 A11 virtual machines was created, each with 112 GB of RAM and 16 cores. By running the tasks in parallel on each virtual machine the total simulation run-time reduced from 80 days on a single machine, to approximately 2 days using Microsoft Azure.
Delivering results through Research-as-a-Service
 To make this large set of results available the team setup an interactive Azure web site that shows simulation results for every European city at https://ceg-research.ncl.ac.uk/ramses/ By hosting the simulation results data in the cloud, it was easy to then create a compelling website to allow people to easily explore this research. You can read the full paper, entitled "Pluvial Flooding in European Cities—A Continental Approach to Urban Flood Modelling", published in the journal Water here.
To make this large set of results available the team setup an interactive Azure web site that shows simulation results for every European city at https://ceg-research.ncl.ac.uk/ramses/ By hosting the simulation results data in the cloud, it was easy to then create a compelling website to allow people to easily explore this research. You can read the full paper, entitled "Pluvial Flooding in European Cities—A Continental Approach to Urban Flood Modelling", published in the journal Water here.
Ramping up your calculations using Microsoft Azure
There are several other ways you can scale your workloads onto multiple machines, depending on what you are used to doing:
- doAzureParallel – a lightweight R package built on top of Azure Batch, that allows you to easily use Azure's flexible compute resources right from your R session.
- Batch Shipyard is a tool to help provision and execute batch processing and HPC Docker workloads on Azure Batch compute pools. No experience with the Azure Batch SDK is needed; run your Dockerized tasks with easy-to-understand configuration files! There is a detailed hands-on walkthrough for this on Github.
- Azure Container Service makes it easy to orchestrate your work using DC/OS, Docker Swarm, or Kubernetes. There is a detailed hands-on walkthrough for this on Github
Need access to Microsoft Azure?
There are several ways you can get access to Microsoft Azure for your research. Your university may already make Azure available to you, so first port of call is to speak to your research computing department. There are also other ways for you to start experimenting with the cloud:
- Sign-up to a one month free trial here
- Apply for an Azure for Research award. Microsoft Azure for Research awards offer large allocations of cloud computing for your research project, and already supports hundreds of researchers worldwide across all domains.
There are several free Azure services for you to also explore:
- Test drive the Linux Data Science Virtual Machine
- Azure Machine Learning
- Azure Jupyter notebooks
- Azure web apps