Azure HDInsight与Hadoop周边系统集成
Sunwei 9 Dec 2014 1:54 AM
传统的Hadoop系统提供给用户2个非常优秀的框架,MR计算框架和HDFS存储框架,尽管MR已经显得有些老迈而缓慢,但是HDFS还是很多应用系统的基石,很多应用都可以把HDFS作为系统的基本数据输入和输出方式。HDFS的基本特征就是数据是分布式切块存储,通过多副本冗余的方式来提供数据持久性保障,并且可以通过节点的增加来进行系统的扩容,这也是很多用户和系统所看重的特点。目前在Hadoop社区里面有各种各样的组件和解决方案用于处理海量数据、可靠性消息、数据分析及预测等多种领域。
Microsoft Azure是一个开放的平台,用户当然可以在Azure上通过运行虚拟机的方式运行Hadoop系统来实现自己的业务功能,但是Azure平台还提供了AzureHDInsight这种PaaS服务来帮助客户更简单的部署和管理他们的Hadoop系统。AzureHDInsight是一套核心的计算组件,请注意我只说了它是负责计算相关的工作。在计算的方面,目前HDInsight提供了3种不同的Cluster类型,标准的Hadoop(HIVE),HBase Cluster,StormCluster,未来Azure还会根据用户的需求引入其他Hadoop的集群。每种不同的Cluster类型我们都进行了针对这个组件相关的一些特殊设计和处理,这样可以针对特定的组件进行优化和配置。从架构上看HDInsight和传统的Hadoop Cluster有一些不同,我们在用户接入层有一层安全网关负责接入客户端请求以及认证,然后将认证后的请求转发到后端可用的headnode上,这种方式不但给Hadoop提供了安全认证以及端口的保护,而且也实现了Name Node的高可用性。如果是HBase Cluster,后端还会有3个zookeeper节点的HA方案。如果用户需要直接访问headnode,我们可以通过将cluster部署到Region VNET的方式来支持,这个功能需要通过Powershell来指定VirtualNetworkId和SubnetName参数来实现,注意这个参数是ID而不是VNET的Name,可以通过(Get-AzureVNetSite-VNetName$VNetName).Id得到,这样就可以将Cluster与你其他的VM放在同一个VNET里面进行直接通信了。另外最近我们在HDInsight上支持了自定义脚本操作,这个功能非常有意义,可以用于安装新的组件例如Spark和R,也可以用来给现有的组件进行补丁的更新,具体的细节你可以参考https://azure.microsoft.com/en-us/documentation/articles/hdinsight-hadoop-script-actions/
除了计算功能之外,Microsoft Azure还提供了功能强大的存储功能,Azure Storage是Azure最基础的服务之一,提供了高持久性、高可用的分布式存储系统完全可以媲美HDFS,所以在HDInsight中我们使用了AzureStorage而不是HDFS的技术,也就是说HDInsight实现了在Hadoop上的计算与存储分离。这样处理的优势非常明显,用户可以根据计算的用量来动态创建和销毁Cluster而不需要考虑数据的问题,只需要保持使用同样的存储账号、容器、基于Azure SQL DB的Hive元数据库。这种基于使用成本的优化方式是传统的Hadoop和HDFS所不能实现的,具体的信息可以参考 https://www.windowsazure.cn/zh-cn/documentation/articles/hdinsight-use-blob-storage/
Hadoop的强大之处并不是因为只有MR和HDFS,发挥更多作用的还是周边的生态系统组件,这些组件不断的在丰富和扩展Hadoop的功能,让客户更加容易的发挥其作用,所以HDInsight必须能够与其他的相关系统进行集成才能与开源社区和客户相连。 在HDInsight平台上除了自身默认支持的功能外,通过自定义脚本操作很多Hadoop周边的系统都可以运行在HDInsight之上,但是而然会有一些周边的系统需要通过HDFS直接与Hadoop系统进行连接,例如用于日志收集的Apache Flume。在这种情况下,为了和Hadoop生态系统保持更好的兼容,微软在Hadoop的source code上也贡献了关于这个部分的源代码,我们可以通过下面的git命令获取ApacheHadoop的源代码并在hadoop-common\hadoop-tools\hadoop-azure下看到在HDFS上支持Azure Storage方面的代码。
git clone git://git.apache.org/hadoop-common.git
通过编译后我们可以将生成的hadoop-azure-3.0.0-SNAPSHOT.jar以及引用的microsoft-windowsazure-storage-sdk-0.6.0.jar复制到你需要的相关Hadoop组件的classpath路径内,然后在hadoopclient中的core-site.xml中添加
<property>
<name>fs.azure.account.key.{youraccount}.blob.core.chinacloudapi.cn</name>
<value>{your key}</value>
</property>
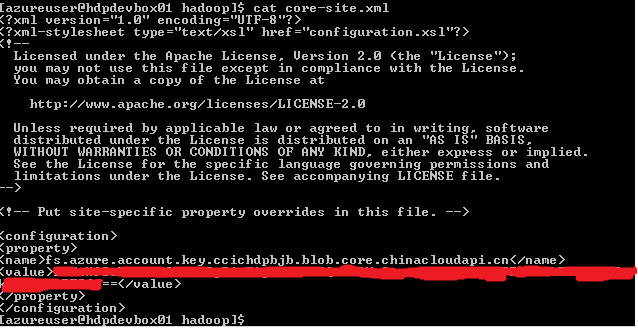
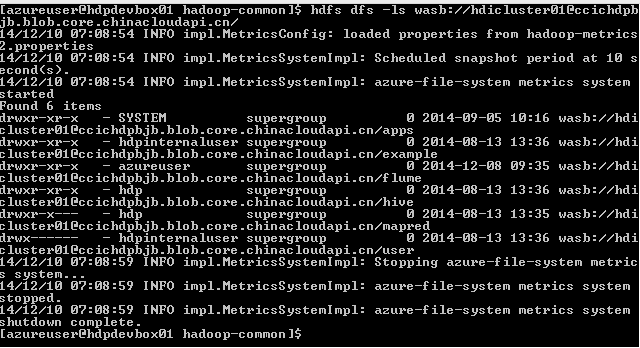
这样Hadoop生态系统中相关的其他系统中通过wasb://来代替hdfs://达到与HDInsight的集成的效果
如果你有任何疑问, 欢迎访问MSDN社区,由专家来为您解答Windows Azure各种技术问题,或者拨打世纪互联客户服务热线400-089-0365/010-84563652咨询各类服务信息。
本文转发自: