DAL – RDBMS 的分区
编辑人员注释: 本文章由AzureCAT 云与企业工程组的高级项目经理 Shaun Tinline-Jones 和 Chris Clayton 共同撰写。
“云服务基础”应用程序也称作“CSFundamentals”,展示如何构建数据库支持的 Azure 服务。这包括描述日志记录、配置和数据访问的使用场景、实施体系结构及可复用组件。代码库旨在用于根据 Windows Azure 客户咨询团队进行的生产部署,深入挖掘在 Azure 上交付可伸缩的可用服务的最佳实践。
目前大多数公司都在努力推进其云计划,但特定解决方案的业务驱动因素各不相同,例如降低成本以及大幅提高敏捷性和扩大规模。当解决方案试图实现“云规模”时,“纵向可伸缩性”战略已被“横向可伸缩性”取代。前者通过升级硬件来提高容量,后者可增加共同完成某个特定任务的计算机数量。此权衡的一个绝佳示例是,选择创建具有许多提供相同网站内容的服务器的 Web 场,还是让单台机体试图处理负载。
大多数人从计算节点着手开始实施此横向可伸缩性计划,但忽略了更复杂且可能更重要的状态层级,例如关系数据库管理系统 (RDBMS) 和缓存。这些服务通常为 IO 密集型,且只有单个实例。在状态层级中实施横向可伸缩性的一个方法称作分区,它是指从逻辑上将 RDBMS 数据分成多个数据库,每个数据库通常采用相同的表结构。例如,一张员工信息表可以拆分到三个不同的数据库,每个数据库存储不同部门员工的信息。
分区的优势远不止体现在与容量相关的场景中。本文章将着重阐述在 Azure SQL 数据库平台中实施的且主要用于 OLTP 场景的 RDBMS 分区。分区数据库结构可带来优势的示例场景包括:
- 限制阀值或吞吐量限制的命中频率过高。
- 数据量太大(索引重新构建、备份等)。
- 一个数据库不可用影响所有用户(而单个分区则不会)。
- 数据库难以按需求向上和向下伸缩。
- 某些业务模型,例如多租户或软件即服务方案。
使用多租户数据库(如 Windows Azure SQL 数据库)作为服务解决方案时,通常会在各种条件下对客户端进行限制的服务质量 (QOS) 控制。限制通常会在资源压力攀升时发生。分区是一种帮助降低资源压力的关键战略,它可以将通常影响单台服务器的负载分散到多台服务器上,每台服务器均包含一个分区。例如,假定负载均匀分配,那么创建五个分区,就可以将每个数据库上的负载降低为大约百分之二十。
但任何东西随着功能变得更强大,也难免要做出一些牺牲。分区可能会增加多个关键领域的复杂性,因此需要更完善的计划。这些关键领域包括:
- 所有分区的标识列应保持全局唯一性,以防将来的业务需求要求减少分区数。如果所有分区的标识不唯一,两个分区合并时会发生冲突。
- 引用完整性无法引用其他分区中的行或者强制与这些行建立关系,因为它们属于独立的数据库。
- 应尽量避免跨分区查询,因为这要求对每个分区进行查询并合并结果。跨分区“扇出”查询不仅从性能角度来说成本极高,而且会增加为其提供支持的分区框架的复杂性。如果必须进行跨分区查询,则通常的策略是对每个分区进行异步查询。但是,有时同步查询方法可以对结果集大小进行更好的控制。
大多数情况下,分区是一个数据访问层 (DAL) 概念,为更高级别的复杂应用程序逻辑抽象化复杂的数据结构。
如何定义“租户”是您构建分区化体系结构时作出的最重要的决策之一。租户是必定位于相同分区上的最大唯一数据分类。限制在单个租户中执行的查询通常速度更快,因为这种查询无需在正常操作状态下执行扇出操作。影响对应租户定义决策的部分因素如下:
- 对标识符的更高级别应用程序代码的了解程度。
- 在此级别上执行大多数核心业务事务的能力。
- 在租户级别避免限制常规日常操作的能力。
为了更形象地说明这些概念和想法,Windows Azure 客户咨询团队在云服务基础 (CSF) 数据包 (https://code.msdn.microsoft.com/Cloud-Service-Fundamentals-4ca72649) 中构建了一个基本分区数据访问层 (DAL)。
CSF 中将租户定义为单个用户。促使选择此租户的因素包括:
- 大多数核心业务需求都不要求跨多用户查询。
- 一个分区不可用只会影响某组用户组,而其他用户可继续正常使用系统。单个分区上的用户数可以控制为企业可承受的数量。
对租户的定义和实施可确保不需要执行跨数据库事务。在图 1 中,我们将此数据集称为 shardlet,即数据模型事务边界。
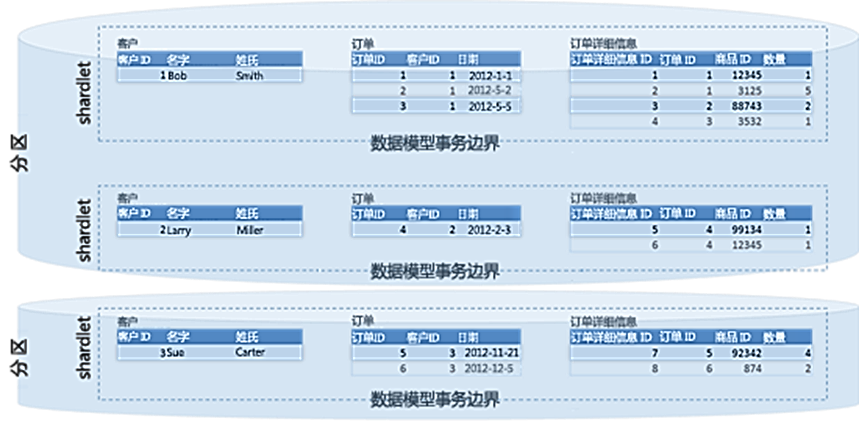
图 1 - 数据模型事务边界
用户首次在会话中连接到数据库时,可以执行一系列简单查询,以了解是否有任何功能由于脱机分区而不可用。
为了简化 CSF 中演示的分区方法,我们决定创建一个分区集,这些分区拥有足以满足可预见将来的容量需求的存储空间。通过选择固定大小,就不再需要演示分区数量的增加和减少,也就无需执行租户迁移之类的操作。通过对租户名称执行哈希算法,可以生成一个整数,此 ID 可用来在“分区图”中查询匹配范围。CSF 使用基于范围的机制,其中一个特定分区(在“分区图”中捕获)将被分配一个这些数字的范围。
如果需要向分区集添加分区或从分区集中删除分区,租户需要在迁移到新分区之前变为不可用。由于此严重限制,因此要求在首次创建分区集时对分区集进行大幅超额配置,以缓解或消除执行复杂分区管理的需要。
此解决方案要求数据访问层 (DAL) 能检测到租户 ID,以确定租户在分区集中的位置。如果执行的查询包括不可用的分区,整个查询将失败。如果 DAL 不包括租户 ID,则必须查询所有分区,这会导致失败概率提高并使性能降低。
目前正在进行一些预备工作,以提供可演示更高级分区方法的更多示例代码。这些示例可改进以下领域:
被动式和主动式分区管理。
- 全局唯一性和标识管理。
- 分区集内分区之间的租户迁移。
- 分区集的扩展和收缩。
- 对无法检测租户的查询的改进。
总而言之,云服务基础示例代码是开始探讨基本分区概念的一个绝佳途径,而分区则是创建“云规模”应用程序的一个重要方法。
本文翻译自:
https://blogs.msdn.com/b/windowsazure/archive/2013/09/05/dal-sharding-of-rdbms.aspx