ISV客户博客系列:Full Scale 180使用Windows Azure处理数据库缩放
编者注: 今天的帖子,由FullScale 180 首席Trent Swanson撰写介绍该公司如何使用 Windows Azure 和数据库分区,为其客户构建可扩展的解决方案。
Full Scale 180是雷德蒙德,一家华盛顿的专门从事云计算解决方案、 提供从专业体系结构咨询到解决方案交付等专业服务的咨询公司。Full Scale 180团队是因为解决看似不可能解决的问题提供Windows Azure上的创新的云计算解决方案而树立名声的。Full Scale 180与跨越广泛的行业的客户工作,虽然每个项目都非常独特,但这些解决方案常有很多共同的考虑和要求。
尽管对于客户有各种不同项目, 设计、实施,公司面临一些非常有趣的挑战,但我们也在 Windows Azure上部署一些非常酷的解决方案。我们经常遭遇的挑战是数据库缩放。
就充分使用数据存储而言,需要集中考虑两点:
- 数据的存储位置
- 存取数据的最佳方式
在软件开发领域中,复杂性和高抽象度的层是非常有趣的一个东西。使用一种手段(这个词代表许多不同的概念,在这里如 API、库、 编程范式、 类库,框架) 来做一些事情,到最终得到一个平衡状态,要么你想出更高级别的抽象构造,要么使用一种来自别人,通常被称为生成/获取的决定。像别的不说,数据存储是按照一样的模式。当处理关系存储,如SQL Azure 时, 您需要按系统设置的规则操作。
数据存储位置
当使用 SQL Azure,数据存储的物理组件不再是你的担忧,所以你不必担心数据文件、 文件组和磁盘已满的状况。你要考虑是服务本身的资源限制。目前 SQL Azure 提供个人数据库为 150 GB。
随着时间推移,普遍预期应用程序的数据库的消费是不断增长的。与非云端数据库不同,您可以控制的唯一维度是附加从 Windows Azure 采购的来的数据库空间。对此有两种方法: 要么计划扩张并提前采购新空间 (这可能破坏运行在云上的目的)要么基于策略自动扩展需求。如果选择后者,我们就需要找到跨数据库的数据分区的方法。
优化数据传输和分片
抛开空间的管理,我们需要确保传入数据和数据存储是快速的。对非云端系统,可以通过优化网络和磁盘的速度。但在云平台上,这通常是不能优化的,所以需要一种不同的方法。通常,这将转化为并行数据访问。
数据存储需求将会增加,但我们需要的是在平台设置的规则里使用最大的数据库。同样地,对于这些规模和吞吐量的限制,我们必须学会设计解决方案。无论是否连接到数据存储,数据存储的物理存储吞吐量,或对数据存储大小的限制,扩展超越这些单位限制往往是需要设计解决方案。如果我们可以采用一种机制,利用一个个小的数据库集合来存储我们的数据,在这里我们可能会并行访问这些较小的数据库,我们就可以优化我们的数据存储解决方案的规模和速度。这里的机制应采取自动数据分区和数据库采购。一个通用的解决办法是分片。使用分片,不论已使用什么方法,数据管理和数据访问将发生变化。 SQL Azure协会为SQL Azure提供了一个出箱分片实施方案。
在我们与一些客户接触时,我们发现SQL Azure的联合将是一个解决方案。除了简单扩大超出150GB单一的数据库大小的限制,我们已经找到了在联合多租户云解决方案是有效的。
SQL Azure Federation多租解决方案
多租户往往是我们通常工作的云计算解决方案的部分的一项要求。这些项目包括创建新的解决方案,添加这些特性到现有的单租解决方案,甚至是重新设计现有的多租户解决方案以达成规模增加和降低运营成本。我们经常发现 SQL Azure Federation是一个非常有用的功能,在满足这些要求下。租户将成为数据分区的一个自然边界,在有大量的租户情况下,管理成本将成为关键。
让我们考虑存储 大概100 KB 的租户数据的解决方案,每个租户的数据存储在自己的数据库中。今天我们可以在 SQL Azure 调配的最小数据库是 100 MB,这相当于租户每月 5 元的存储成本。如果我们有10,000 租户,基准成本 现在是 5 万元 !现在们可以将所有租户都合并到单个数据库中,而不是单独的数据库。即使每名租户都存储满 100 KB 的数据,我们可以以2 GB 数据库符合所有 10,000 租户,而且还有剩余,计算成本我们每月只有$13.99。这是很大的不同 !
现在让我们来考虑添加到我们服务的新功能,这将需要更多的数据库来存储,同时我们将继续为租户提供存储。我们当然可以增加数据库的大小,以适应需求增加,但有些时候,我们会到一个限制。此限制既可能是数据库的大小上限也可能是单个数据库在能够接受的时间处理的事件数量。这使分片变得极为有用, SQL Azure Federation将很高兴知道有些时候服务仍然处于在线状态时,我们可以简单地分裂我们的数据库,并扩展我们的数据库以满足日益增长的需求。
我们最近开发的一些示例演示了 Windows Azure 多租户解决方案。这些示例之一包括利用 SQL Azure Federation多租户的示例应用程序,你可以在shard.codplex.com找到。让我们看一个基于分片示例项目
将多租户添加到现有的解决方案
移动单租客数据库到共享数据库的方法往往是很昂贵。常用的方法是,将租客标识符添加到包含特定于租客的每个数据表,然后重做包括租赁所有图层中的应用。另外,为了支持扩展到单个资源有限的数据库,租户必须跨多个数据库分发。作为回报,解决方案的经营成本将降低,即增加利润或让出租软件供应商的解决方案更具有价格竞争力。在过去,我们基本上会以客户分片方案来减少花费和支持规模。这些自定义解决方案了提供设计复杂的单一的 DB 租客级的分离,来处理的连接路由和移动租户跨数据库以满足日益增长的需求。
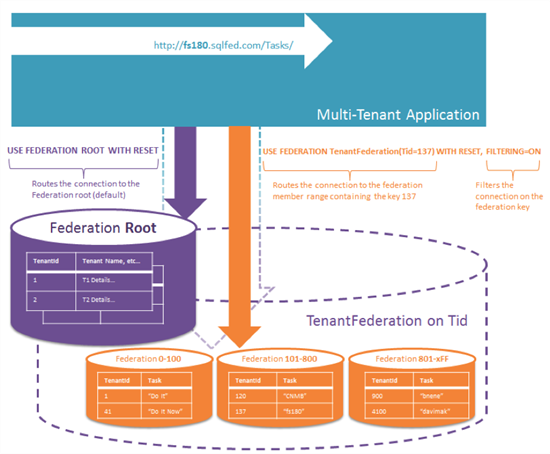
连接筛选
SQL Azure Federation筛选连接功能强大是在与将现有的解决方案移动到设计的共享数据库。已筛选的连接可用于最小化更改必要的业务逻辑或数据访问层,通常使用租客 ID 是所有操作必要的一部分。一旦我们的数据库连接与租客上下文初始化之后我们可以使用与预先存在的业务逻辑和数据访问层的连接。尽管此功能用于最小化应用程序中所需的工作,在架构中的更改仍然是必要、 数据层小的变动,也是需要的并且有时由于使用联合会中不受支持功能的应用程序更改可能有必要。在 MSDN 上可以找到的SQL Azure Federation准则和限制的详细信息。
即使我们为多个租户添加[TenantId] 列到架构以将数据存储在同一个表中,我们不一定要改变我们的代码或我们的模型来处理这些。例如,假设我们有个表包含一些任务,并且为租客应用程序中的一些功能是插入和显示该表中的任务。将 TenantId 列添加到表中后,未经筛选连接,任何代码包含类似于下面的 SQL 语句
SELECT * FROM [Tasks]
需要修改成这样:
SELECT * FROM [Tasks] WHERE TenantId = @TenantId
事实上,几乎所有的代码包含这样的 SQL 语句将需要更改。与筛选连接,使用下面的语句的应用程序代码" SELECT * FROM [Tasks]"将不需要更改。
架构更改
经过快速审查以确定在架构和各种解决方法不受支持功能的使用,我们首先确定联合的所有表。任何包含特定于租客的数据的用于分区的表将要求租客 id 列在表上。此外,任何表包含外键约束,引用联合的表,也需要添加TenantId,并成为联合的表。例如,想象一下,如果我们有订单表,我们决定将联合的表。此表会有OrderId,和很多订单明细表,该表将包含OrderId订单表的外键约束。订单明细还需要添加的 TenantId 列和外键约束也将需要包含 TenantId。
这些联合的表中的每个我们也将默认的租客 id 用于在建立筛选的连接上下文,以便插入新记录时的业务逻辑或数据访问层不需要传递的租客的 id 值作为操作的一部分。
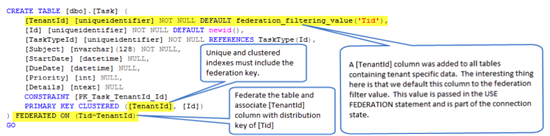
[TenantId] 列添加到包含特定于租客的数据的所有表。此列被默认为联邦筛选器的值,这是经过筛选的连接上使用联邦语句和连接状态的一部分中传递的值。此功能允许我们以将数据插入到联合表而不必包括 [TenantId] 作为声明的一部分。现在目前不处理租赁的数据访问代码将不需要改变,以支持这个新列,当插入新记录。联合的表上的所有独特和聚集索引必须包括联合的列中,所以我们也做了主键的这一部分。"联合在"on 子句添加到使其联合的表,在这我们 [TenantId] 表的列与相关联的 [工贸署] 联邦分布的关键。
连接上下文
现在,我们的架构已更新,我们需要解决应用程序中获取连接筛选。这里的挑战是要初始化的租客的上下文,需要调用特定的联邦语句 (" USE FEDERATION…”),连接打开后,应用程序将使用此连接之前需要我们的数据库连接。这可以通过实施租客标识符的方法来实现,要么与某些事件处理程序处理这种逻辑,在打开连接时返回一个打开的连接的应用程序使用或连接对象。
合在一起
让我们把这一起典型的多租户解步行通过一个简单的 web 请求的完整过程。在此示例中,我们会考虑我们如何联合的任务表写入一个新的任务和为租客返回的任务的列表。
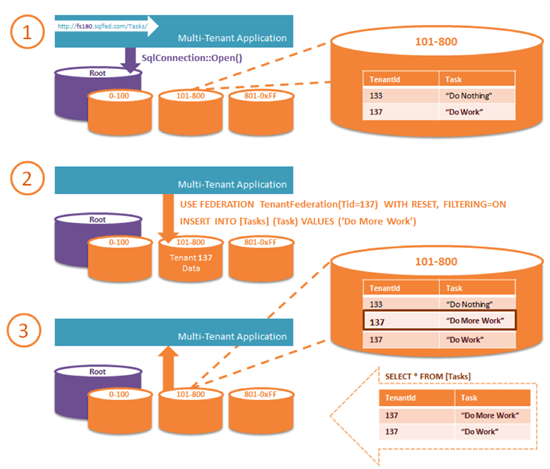
1) 我们收到 web 请求与我们的任务信息、 数据进行验证,并请求的租客上下文建立。我们如何解决租客标识符是另一个的讨论,这是可以使用多种不同方法处理的东西。我们将在租客标识符传递给方法检索与租客上下文初始化的数据库连接。
- 这也可以返回了一个打开的连接" USE FEDERATION TenantFederation(Tid=137) WITH RESET, FILTERING=ON "执行语句。
- 我们可以将事件处理程序附加到连接状态更改为打开时执行此语句的连接对象
- 有许多方法可用,如果利用实体框架 ;例如环绕现有 SQL 提供程序、 连接对象,或简单地返回与连接上下文的附加和事件处理程序打开和初始化。
2)"使用联邦"语句重定向到正确的联邦成员包含数据的租客 id 137 的连接。应用程序然后可以使用此筛选的连接到底它是怎么当在数据库中只有一个租客的数据
INSERT INTO [Task] ([Name], …) VALUES (‘My Task’, …)
1.请注意有不需要包含 TenantId 值
3) 检索任务返回的视图 — — SELECT * FROM [Tasks]
1. 请注意有无需包括 WHERE 子句与 TenantId
随着我们的系统的增长和我们板载更多住户,我们现在有一种体系结构,允许我们可以动态地调整出数据库。我们分裂联邦、 和应用程序仍然在线时我们已扩展到我们出的解决方案跨另一个数据库。
SQL Azure Federation在客户分片位置
我们的一些客户已经实施自定义尽可能解决方案。如果它工作,它似乎像我们不该打扰更改的解决方案利用 SQL Azure Federation。我们仍然 SQL Azure Federation会与他们商讨,如有通过联合会所获得的好处:
- 租客迁移。 有时,很难预测哪些租户将会小型、 中型或大型寄宿的过程中,使它难以处理这些租户不断变化的资源需要。租客可能需要移动到其自己的数据库或现有数据库可能需要拆分处理系统上的需求增加。SQL Azure Federation支持联机数据库拆分。
- 租客不可知论者查询。 与自定义的碎片,可能的数据访问层及其查询中包括的租客 ID。与 SQL Azure Federation,连接筛选器提供租客层筛选,允许查询来写而不需要包括租客 id。
- 数据库查找。 通常,在多租户的应用程序中,master 数据库所有的租客数据库 (共享的数据库或单个数据库,取决于应用程序的数据库拓扑映射住户) 提供了查找索引。与 SQL Azure Federation,租客级连接字符串会自动连接到相应的数据库,可省却管理主查阅数据库的连接字符串。
- 连接池碎片。 一种自定义尽可能的实现将利用多个数据库,这些数据库,因此多个连接和连接字符串。每个这些连接将导致连接池的应用程序服务器,通常通往池碎片应用程序中的问题。支持解决方案所需的数据库的数量取决于这可能会导致性能问题,有时唯一的选项是一个复杂的重新设计或需要禁用连接池。这不是 SQL Azure Federation的情况,如Federation的连接的处理很多不同,导致在单个连接池。
总结
SQL Azure Federation应该考虑和评估与任何可以动态地扩展在 Windows Azure 的关系数据库要求的解决方案。它肯定应考虑与新的或现有的任何多租户解决方案。我推荐从下面的资料开始,获得更多有关SQL Azure Federations的信息。