Improving SSRS Report Performance at Line level – Part 5
Inevitably, we can’t completely get rid of all line-based data accesses or calculations. So, we discuss here a few ways to improve without change the basic report logic.
Remove duplicated DB calls
Most of the duplicated DB calls are hidden deep in the stack. For example, Vendor report calls DirPartyTable::ElectornicAddressType2primaryFieldId() 4 times (4 db access) per line, from VendTable::email, telefax, telex, and phone methods, respectively.
The case of duplicated DB call are mostly implicit, such as calling find() method inside a table method. Some of them are cached in the global cache, some are not. You need to make the decision whether we use global cache, or fix it at the report level. (Note that cache approach won’t help in cold start case.)
A way to detect this pattern is to run a report under the tracer and analyze the trace by comparing number of report lines with number of DB method calls in a code path. Say if a report has 100 output lines and a corresponding DB method call count is 200, then you should exam further if the duplicated method call can be reduced.
More report examples are ProdPickList report, LedgerJournal report, CustInvinoiceSpec report, etc.
Refactor Parent Level Operations
Sometimes, parent level information is retrieved or calculated at the detail level. It causes repeated data access or calculation. An example is that Customer or Company field values are retrieved through CustTrans table method. One way to fix it is to cache the values in global cache. However, adding them to cache will encure system wide impact. Secondly, caching does not help in case of cold start.
There are two ways to fix it. First, try to sort the query data source by parent level field values, Customer RecID in the above case, and get the new data row only if a change occurs. This way, we can reuse the parent level values in the subsequent lines until parent record changed.
Another way to fix is to separate parent level values with the details by processing parent level values outside the loop of lines. You can likely use set-based operations at parent level and join the result with the line-based result. Here is an example from CustInvoice report:
while (queryRun.next()) { ... summaryAccount = this.getSummaryAccount(custTrans.AccountNum, custTrans.PostingProfile); if (dimensionFocusName != '' && summaryAccount != 0) { dimensionFocusDisplayValue = DimensionStorage::getDisplayValueForFocusName(summaryAccount, dimensionFocusName); } ... } |
In Contoso as an example, CustTran table has 10,000 records. The number of combinations of the two keys, AccountNum and PostingProfile, is just over 100, which is the total number of summaryAccount records. The current code use a Map to cache the result in memory, but it is still a line-based look up.
To optimize it, you can save the result of getSummaryAccount() in a lookup temp table, keyed by AccountNum and PostingProfile. Here are the new steps in the sequence:
- Update the main while loop by removing call to getSummaryAccount() method and the logic after to get display names. You need to added AccountNum and PostingProfile in to the temp table and save the field values in the insert method.
- Add a set-based insert after the main loop into the lookup temp table from custInvoiceTmp table, with group by the two key fields.
- Add a select-while loop to the lookup temp table to call getSummaryAccount method and getDisplayValueForFocusName method; save the display name in the same table using update. Note that you don’t need the map look up anymore.
- Add a set-based update to set the DismensionFocusDisplayValue field in CusInvoiceTmp table by joining the lookup temp table on the key fields.
- Optional of doing step 3 and 4, you can avoid calling getDisplayValueForFocusName method line-by-line in step 3 by duplicate its logic with the set-based update in step 4 above; just add another join.
This pattern applies not only to the parent-child tables, but also to any cases that the field values of a temp table comes from a table with much fewer distinct lines, say with ratio of 1:10 or larger.
Fewer Instantiations of Helper Class Objects
A typical example of this pattern is the use of CurrencyExchangeHelper, which instantiates an object for each line. The cost can become significant. In PurchRanking report for example, it takes up to 60% of total processing time.
You can try to instantiate one instance for the entire process; and then assign different parameters in the iteration of lines for calling calculations.
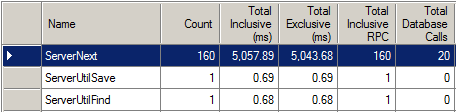
Skip postLoad Kernel Call
After a data row is loaded, Ax kernel makes a call back to application postLoad() override method, which will give application the first chance to tweak the data or fire dependency logic. If the table used by your report does have the method override, you can improve the report performance by telling the Ax kernel to skip the method call. Report developers must make the decision to see if the postLoad override method can be skipped in the context of the report.
In one measurement, we see about 5% of performance improvement just on the method call overhead. The saving could be more significant considering the time spend on processing the method logic.
Here is the code to show how to do it:
static void Job2(Args _args) { QueryRun queryCreatePayment; Query query; VendTrans vendTrans; QueryBuildDataSource qbds; VendTrans vendTransTable;
query = new Query(queryStr(VendPaymProposal)); qbds = query.dataSourceName('VendTrans'); vendTransTable = qbds.getNo(); vendTransTable.skipPostLoad(true); //set it to true to skip the call
queryCreatePayment = new QueryRun(query); queryCreatePayment.setRecord(vendTransTable); //Trick is here that we have to set the record while (queryCreatePayment.next()) { vendTrans = queryCreatePayment.get(tableNum(VendTrans)); } } |
And, here is the trace comparison between a normal default trace and the trace with the skipping enabled. The postLoad method here does not do much:
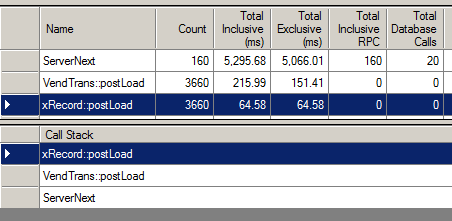
With skippostLoad set to true, the extra calls are gone: