Ledger account combinations - Part 7 (Advanced topics)
Introduction
Concluding this series of blog posts, we will discuss some of the advanced topics that explain some of the deeper design and implementation decisions that drive the way the dimension framework works.
The model below in figure 1 shows the various areas within the dimension framework.
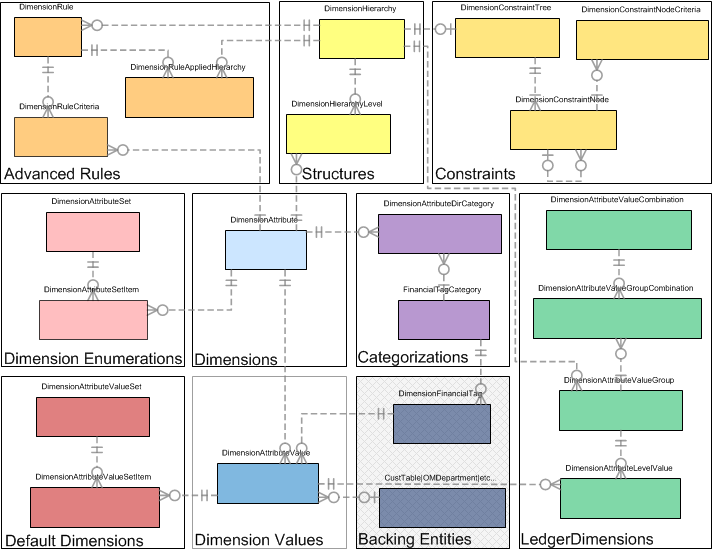
Figure 1: Overall framework
Hashes
The design of the database storage in the dimension framework intends to:
- Support immutable data where data is only inserted, never updated or deleted
- Reuse previously created combinations to lower insertion costs
- Avoid reference counting and maintenance of it
- Provide fast performance to find an existing combination for reuse
As the dimension framework allows unlimited dimensions and unlimited structures on a ledger account combination, it is difficult to create a single large or multiple smaller queries to find an existing set or combination. Since the number of records and order of those records is potentially different for every combination, a hash-based solution was implemented.
This hash represents the unique information contained in the associated tables' records for fast querying. A single binary container field (160 bit, 20 byte hash column) is stored to uniquely identify the data contained by the set or combination.
The dimension framework uses hashes to uniquely identify data in the following tables:
- DimensionAttributeValueCombination
- Consisting of data from all the linked records in the DimensionAttributeValueGroup and DimensionAttributeLevelValue tables
- DimensionAttributeValueGroup
- Consisting of data from the linked records in the DimensionAttributeLevelValue table
- DimensionAttributeSet
- Consisting of data from the associated DimensionAttributeSetItem records
- DimensionAttributeValueSet
- Consisting of data from the associated DimensionAttributeValueSetItem records
Hash messages
In order to produce a hash, a message is created containing individual ordered information about the contents of the set or combination. It varies based upon the particular hash being generated, but basically includes information about the dimensions, values, and structures and their order within the set or combination, if applicable. This information is internally calculated in a prescribed manner and passed onto a hashing routine to generate a SHA-1 hash to persist using a binary container. The exact order and contents of these messages are provided by the methods within the storage supporting classes of the dimension framework including the DimensionAttributeSetStorage, DimensionAttributeValueSetStorage, and DimensionStorage classes.
HashKeys
In order to generate a hash message, something that uniquely identifies each dimension, value and structure that makes up the combination is needed. While a RecID can serve as a unique identifier, it is only considered a surrogate, as it is not immutable and can change if the record were to be exported and imported into a different system or partition, for example. The RecID can be reassigned during the import process. Any hash that was created with a hash message using a RecID could no longer be used to identify a combination in the dimension framework for that new system or partition. Instead another identifier, a GUID, is used. This GUID resides on the DimensionAttribute, DimensionAttributeValue and DimensionHierarchy tables and is stored in the HashKey column. Each time a new record is created, a GUID is assigned and remains with that record to uniquely identify it.
Risks of changing data directly
It is extremely important that no data be directly modified outside of the application framework such as in SQL Server Management Studio. This extends to modifying any data in any column of the table not just the columns discussed in these posts; as well as replicating data from one row to another and attempting to create 'new' sets or combinations outside of the dimension framework storage classes.
It is also important to understand this when considering backups and only partial restoration of data which could affect referential and hash integrity. For example, it would be problematic to only back up the LedgerDimension related records and importing them into another partition without also bringing in all of the other records in the dimension framework as well as all of the backing entity records such as from the CustTable or others that were used in the creation of any combinations. Any attempts to modify the data in these tables or to synthesize GUIDs or hashes will lead to corrupt data and complex time consuming analysis to find the source of the corruption and to try to undo it.
Apparent duplicate combinations
When browsing the tables of the dimension framework, it may appear that combinations are duplicated when only viewing the DisplayValue field stored on the records. This does not mean that duplicate combinations exist; rather it means that data within the hash or joined tables is different even though the DisplayValue appears the same. The DisplayValue strings are stored on the records to improve performance for some scenarios but are not used to uniquely identify the record.
Consider an account structure with [ MainAccount - Department ] in one company and another account structure with [ MainAccount - CostCenter ] in a different company. It is possible for the DisplayValue of 2 combinations, one for each account structure, to appear as " 145 - A ". For the first account structure "A" represents a Department within that company, but for the second it represents a Cost center within that company. Additionally, there are multiple types of a LedgerDimension that are stored in the DimensionAttributeValueCombination table including special ones for budgeting that may appear the same from examining the DisplayValue field as other combinations ones but hold different information internally and hold uniquely different hash values.
Versioning / date effective data
The dimension framework does not support versioning or date effective data directly. If any backing entities it references are versioned, and a new RecID assigned to newer versions within the same table, the framework will properly link to the correct version through the DimensionAttributeValue record. If the same backing entity record is used and another table tracks revisions to it in the owning module, then the dimension framework will not be able to know the difference as the backing entity RecID would not be different between versions. None of the dimension framework tables (such as dimensions, structures, rules, constraints) internally support versioning. The previous versions are replaced with a new version with no history maintained.
When a structure or rule is changed, and there are ledger account combinations saved on unposted transactions, the dimension framework will create new combinations and update any foreign key references to them on unposted transaction tables. It will not change the original combinations as they may be referenced from posted transactions. The two combinations are not linked in any way. There is not a way to determine the way a structure and its rules appeared prior to change. Some information can be determined by the data stored in the combination, but since blank values are not stored, it is incomplete and cannot be used to reconstruct a previous version.
The dimension framework does supports valid from and valid to dates at the level of a dimension value. This indicates when the value is considered "valid" and does not represent the historical state of the value in the same way that date effective data does.
This concludes this series of blog posts about the dimension framework and “What happens when I create a ledger account combination?”