HDInsight (Hadoop on Azure) Demo: Submit MapReduce job, process result from Pig and filter final results in Hive
In this demo we will submit a WordCount map reduce job to HDInsight cluster and process the results in Pig and then filter the results in Hive by storing structured results into a table.
Step 1: Submitting WordCount MapReduce Job to 4 node HDInsight cluster:
c:\apps\dist\hadoop-1.1.0-SNAPSHOT\bin\hadoop.cmd jar c:\apps\Jobs\templates\635000448534317551.hadoop-examples.jar wordcount /user/admin/DaVinci.txt /user/admin/outcount

The results are stored @ /user/admin/outcount
Verify the results at Interactive Shell:
js> #ls /user/admin/outcount
Found 2 items
-rwxrwxrwx 1 admin supergroup 0 2013-03-28 05:22 /user/admin/outcount/_SUCCESS
-rwxrwxrwx 1 admin supergroup 337623 2013-03-28 05:22 /user/admin/outcount/part-r-00000
Step 2: loading /user/admin/outcount/part-r-00000 results in the Pig:
First we are storing the flat text file data as words, wordCount format as below:
Grunt>mydata = load '/user/admin/output/part-r-00000′ using PigStorage('\t') as (words:chararray, wordCount:int);
Grunt>first10 = LIMIT mydata 10;
Grunt>dump first10;
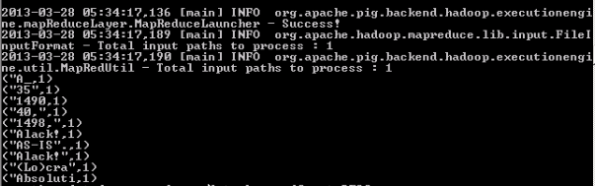
Note: This shows results for the words with frequency 1. We need to reorder to results on descending order to get words with top frequency.
Grunt>mydatadsc = order mydata by wordCount DESC;
Grunt>first10 = LIMIT mydatadsc 10;
Grunt>dump first10;

Now we have got the result as expected. Lets stored the results into a file at HDFS.
Grunt>Store first10 into '/user/avkash/myresults10' ;
Step 3: Filtering Pig Results in to Hive Table:
First we will create a table in Hive using the same format (words and wordcount separated by comma)
hive> create table wordslist10(words string, wordscount int) row format delimited fields terminated by ',' lines terminated by '\n';
Now once table is created we will load the hive store file '/user/admin/myresults10/part-r-00000′ into wordslist10 table we just created:
hive> load data inpath '/user/admin/myresults10/part-r-00000′ overwrite into table wordslist10;
That's all as you can see the results now in table:
hive> select * from wordslist10;

KeyWords: Apache Hadoop, MapReduce, Pig, Hive, HDInsight, BigData