Setting Windows Azure Blob Storage (asv) as data source directly from Portal at Hadoop on Azure
After you log into your Hadoop Portal and configured your cluster, you can select “Manage Data” tile as below:
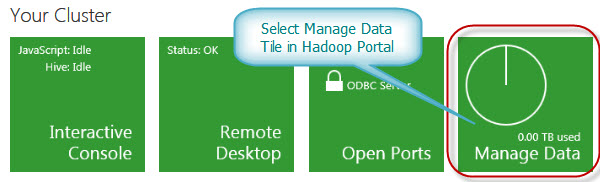
On the next screen you can select:
- “Set up ASV” to set your Windows Azure Blob Storage as data source
- “Set up S3” to set your Amazon S3 Storage as data source
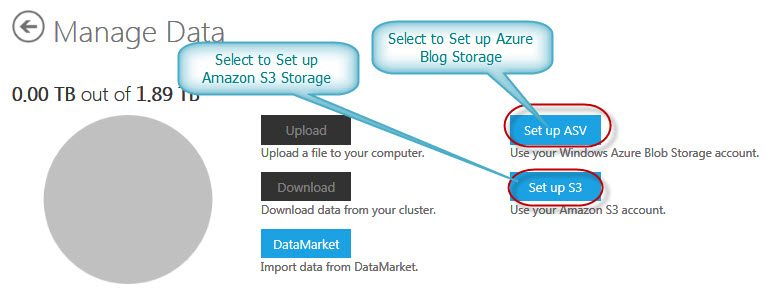
When you select “Set up ASV”, in the next screen you would need to enter your Windows Azure Storage Name and key as below:
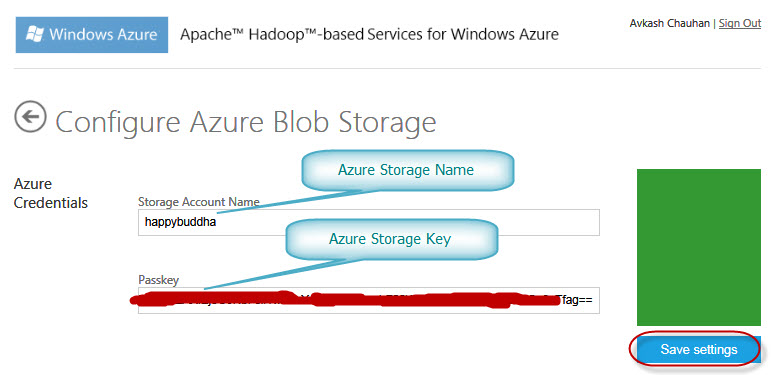
After you select “Save Settings”, if you Azure Storage credentials are correct you will get the following message:

Now you Azure Blob Storage is set up to use with Interactive JavaScript shell or you can remote into your cluster to access from there as well. You can test it directly at Interactive JavaScript shell as below:
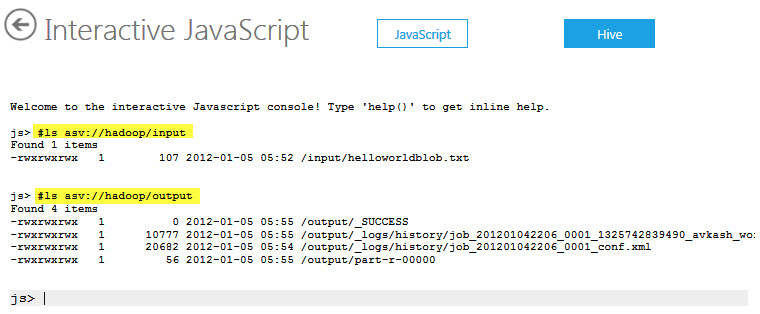
Note: If you really want to know how Azure Blob Storage was configured with Hadoop, it was done by adding proper Azure Storage credentials into core-site.xml as below:
If you open C:\Apps\Dist\conf\core-site.xml you will see the following parameters related with Azure Blob Storage access from Hadoop Cluster:
<property> <name>fs.azure.buffer.dir</name> <value>/tmp</value> </property> <property> <name>fs.azure.storageConnectionString</name> <value>DefaultEndpointsProtocol=https;AccountName=happybuddha;AccountKey=***********************************************************==</value> </property> |
More info is here:
Resources:
- Apache Hadoop on Windows Azure Technet WiKi
- Keywords: Apache Hadoop, Windows Azure, BigData, Cloud, MapReduce