Apache Hadoop on Windows Azure: Connecting to Windows Azure Storage from Hadoop Cluster
Microsoft distribution to Apache Hadoop comes by direct connectivity to cloud storage i.e. Windows Azure Blob storage or Amazon S3. Here we will learn how to connect your Windows Azure Storage directly from your Hadoop Cluster.
As you know Windows Azure Storage access needed following two things:
- Azure Storage Name
- Azure Storage Access Key
Using above information we create the following Storage Connection Strings:
- DefaultEndpointsProtocol=https;
- AccountName=<Your_Azure_Blob_Storage_Name>;
- AccountKey=<Azure_Storage_Key>
Now we just need to setup the above information inside the Hadoop cluster configuration. To do that, please open C:\Apps\Dist\conf\core-site.xml and include the following to parameters related with Azure Blob Storage access from Hadoop Cluster:
<property> <name>fs.azure.buffer.dir</name> <value>/tmp</value> </property> <property> <name>fs.azure.storageConnectionString</name> <value>DefaultEndpointsProtocol=https;AccountName=<YourAzureBlobStoreName>;AccountKey=<YourAzurePrimaryKey></value> </property> |
The above configuration setup Azure Blob Storage within the Hadoop setup.
ASV:// => https://<Azure_Blob_Storage_name>.blob.core.windows.net
Now let’s try to list the blogs in your specific container:
c:\apps\dist>hadoop fs -lsr asv://hadoop/input
-rwxrwxrwx 1 107 2012-01-05 05:52 /input/helloworldblob.txt
Let’s verify at Azure Storage that the results we received above are correct as below:
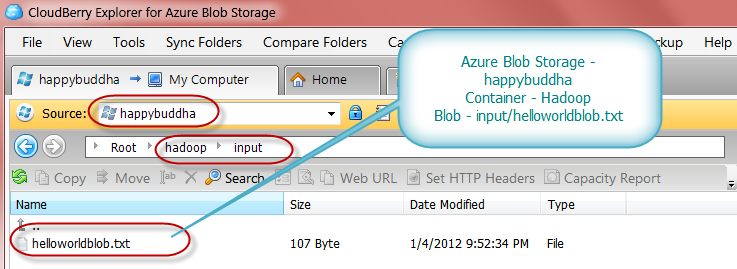
So for example if you would want to copy a file from Hadoop cluster to Azure Storage you will use the following command:
Hadoop fs –copyFromLocal <Filename> asv:// <Target_Container_Name> / <Blob_Name_or_samefilename>
Example:
c:\Apps>hadoop.cmd fs -copyFromLocal helloworld.txt asv://filefromhadoop/helloworldblob.txt
This will upload helloworld.txt file to container name “filefromhadoop” as blob name “helloworldblob.txt”.
c:\Apps>hadoop.cmd fs -copyToLocal asv://hadoop/input/helloworldblob.txt helloworldblob.txt
This command will download helloworldblob.txt blob from Azure storage and made available to local Hadoop cluster
Please see below to learn more about “Hadoop fs” command:
c:\Apps>hadoop fs Usage: java FsShell [-ls <path>] [-lsr <path>] [-du <path>] [-dus <path>] [-count[-q] <path>] [-mv <src> <dst>] [-cp <src> <dst>] [-rm [-skipTrash] <path>] [-rmr [-skipTrash] <path>] [-expunge] [-put <localsrc> ... <dst>] [-copyFromLocal <localsrc> ... <dst>] [-moveFromLocal <localsrc> ... <dst>] [-get [-ignoreCrc] [-crc] <src> <localdst>] [-getmerge <src> <localdst> [addnl]] [-cat <src>] [-text <src>] [-copyToLocal [-ignoreCrc] [-crc] <src> <localdst>] [-moveToLocal [-crc] <src> <localdst>] [-mkdir <path>] [-setrep [-R] [-w] <rep> <path/file>] [-touchz <path>] [-test -[ezd] <path>] [-stat [format] <path>] [-tail [-f] <file>] [-chmod [-R] <MODE[,MODE]... | OCTALMODE> PATH...] [-chown [-R] [OWNER][:[GROUP]] PATH...] [-chgrp [-R] GROUP PATH...] [-help [cmd]]
Generic options supported are -conf <configuration file> specify an application configuration file -D <property=value> use value for given property -fs <local|namenode:port> specify a namenode -jt <local|jobtracker:port> specify a job tracker -files <comma separated list of files> specify comma separated files to be copied to the map reduce cluster -libjars <comma separated list of jars> specify comma separated jar files to include in the classpath. -archives <comma separated list of archives> specify comma separated archives to be unarchived on the compute machines.
The general command line syntax is bin/hadoop command [genericOptions] [commandOptions] |
Keywords: Windows Azure, Hadoop, Apache, BigData, Cloud, MapReduce