Apache Hadoop on Windows Azure Part 10 - Running a JavaScript Map/Reduce Job from Interactive JavaScript Console
Microsoft distribution of Apache Hadoop on Windows Azure, let you run JavaScript Map/Reduce jobs directly from web based Interactive JavaScript Console. To start with lets write a JavaScript code for Map/Reduce wordcount jobs as below:
FileName #Wordcount.js:
var map = function (key, value, context) {
var words = value.split(/[^a-zA-Z]/);
for (var i = 0; i < words.length; i++) {
if (words[i] !== "") {
context.write(words[i].toLowerCase(), 1);
}
}
};var reduce = function (key, values, context) {
var sum = 0;
while (values.hasNext()) {
sum += parseInt(values.next());
}
context.write(key, sum);
};
After that you can upload this wordcount.js file to HDFS and verify it as below:
js> fs.put()
js> #ls
Found 2 items
drwxr-xr-x - avkash supergroup 0 2012-01-02 20:25 /user/avkash/.oink
-rw-r--r-- 3 avkash supergroup 418 2012-01-02 20:17 /user/avkash/wordcount.js
Now you can create a folder name “wordsfolder” and upload a few txt files. We will use this folder as input folder to run the word count map/reduce job.
js> #ls
Found 3 items
drwxr-xr-x - avkash supergroup 0 2012-01-02 20:25 /user/avkash/.oink
-rw-r--r-- 3 avkash supergroup 418 2012-01-02 20:17 /user/avkash/wordcount.js
drwxr-xr-x - avkash supergroup 0 2012-01-02 20:22 /user/avkash/wordsfolder
js> #ls wordsfolder
Found 3 items
-rw-r--r-- 3 avkash supergroup 1395667 2012-01-02 20:22 /user/avkash/wordsfolder/davinci.txt
-rw-r--r-- 3 avkash supergroup 674762 2012-01-02 20:22 /user/avkash/wordsfolder/outlineofscience.txt
-rw-r--r-- 3 avkash supergroup 1573044 2012-01-02 20:22 /user/avkash/wordsfolder/ulysses.txt
Now we can run the JavaScript Map/Reduce job to count the top 15 words in descending order in the folder name “top15words” as below:
js> from("wordsfolder").mapReduce("wordcount.js", "word, count:long").orderBy("count DESC").take(15).to("top15words")
View Log
If you click the “View Log” link above in a new tab, you can see the activity about Map/Reduce job which I have added at the end of this blog:
Finally when the job is completed, the following folder “top15words” will be created as below:
js> #ls
Found 4 items
drwxr-xr-x - avkash supergroup 0 2012-01-02 20:26 /user/avkash/.oink
drwxr-xr-x - avkash supergroup 0 2012-01-02 20:31 /user/avkash/top15words
-rw-r--r-- 3 avkash supergroup 418 2012-01-02 20:17 /user/avkash/wordcount.js
drwxr-xr-x - avkash supergroup 0 2012-01-02 20:22 /user/avkash/wordsfolder
Now we can read the data from the “top15words” folder:
js> file = fs.read("top15words")
the 47430
of 25263
and 18664
a 14213
in 13125
to 12634
is 7876
that 7057
it 7005
on 5081
he 5037
with 4931
his 4314
as 4289
by 4119
Let’s parse the data also:
js> data = parse(file.data,"word, count:long")
[
0: {
word: "the"
count: 47430
}
1: {
word: "of"
count: 25263
}
2: {
word: "and"
count: 18664
}
3: {
word: "a"
count: 14213
}
4: {
word: "in"
count: 13125
}
5: {
word: "to"
count: 12634
}
6: {
word: "is"
count: 7876
}
7: {
word: "that"
count: 7057
}
8: {
word: "it"
count: 7005
}
9: {
word: "on"
count: 5081
}
10: {
word: "he"
count: 5037
}
11: {
word: "with"
count: 4931
}
12: {
word: "his"
count: 4314
}
13: {
word: "as"
count: 4289
}
14: {
word: "by"
count: 4119
}
]
Finally lets create a line graph from the results:
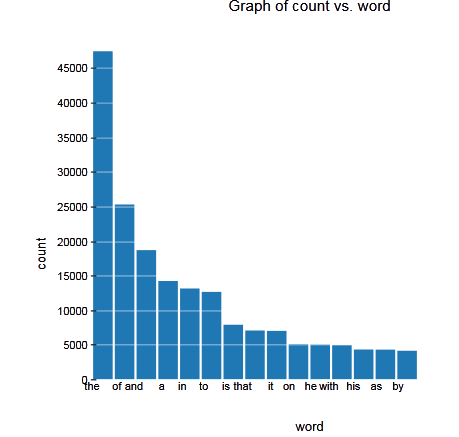
Here is the Map/Reduce Job results:
2012-01-02 20:26:52,304 [main] INFO org.apache.pig.Main - Logging error messages to: c:\apps\dist\bin\pig_1325536012304.log 2012-01-02 20:26:52,570 [main] INFO org.apache.pig.backend.hadoop.executionengine.HExecutionEngine - Connecting to hadoop file system at: hdfs://10.26.104.45:9000 2012-01-02 20:26:53,038 [main] INFO org.apache.pig.backend.hadoop.executionengine.HExecutionEngine - Connecting to map-reduce job tracker at: 10.26.104.45:9010 2012-01-02 20:26:53,304 [main] INFO org.apache.pig.tools.pigstats.ScriptState - Pig features used in the script: ORDER_BY,LIMIT,NATIVE 2012-01-02 20:26:53,304 [main] INFO org.apache.pig.backend.hadoop.executionengine.HExecutionEngine - pig.usenewlogicalplan is set to true. New logical plan will be used. 2012-01-02 20:26:53,507 [main] INFO org.apache.pig.backend.hadoop.executionengine.HExecutionEngine - (Name: q2: Store(hdfs://10.26.104.45:9000/user/avkash/top15words:org.apache.pig.builtin.PigStorage) - scope-12 Operator Key: scope-12) 2012-01-02 20:26:53,523 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MRCompiler - File concatenation threshold: 100 optimistic? false 2012-01-02 20:26:53,742 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MultiQueryOptimizer - MR plan size before optimization: 5 2012-01-02 20:26:53,742 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MultiQueryOptimizer - MR plan size after optimization: 5 2012-01-02 20:26:53,945 [main] INFO org.apache.pig.tools.pigstats.ScriptState - Pig script settings are added to the job 2012-01-02 20:26:53,992 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.JobControlCompiler - mapred.job.reduce.markreset.buffer.percent is not set, set to default 0.3 2012-01-02 20:26:55,179 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.JobControlCompiler - Setting up single store job 2012-01-02 20:26:55,210 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MapReduceLauncher - 1 map-reduce job(s) waiting for submission. 2012-01-02 20:26:55,710 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MapReduceLauncher - 0% complete 2012-01-02 20:26:55,835 [Thread-4] INFO org.apache.hadoop.mapreduce.lib.input.FileInputFormat - Total input paths to process : 3 2012-01-02 20:26:55,835 [Thread-4] INFO org.apache.pig.backend.hadoop.executionengine.util.MapRedUtil - Total input paths to process : 3 2012-01-02 20:26:55,882 [Thread-4] INFO org.apache.pig.backend.hadoop.executionengine.util.MapRedUtil - Total input paths (combined) to process : 1 2012-01-02 20:26:57,226 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MapReduceLauncher - HadoopJobId: job_201201021955_0002 2012-01-02 20:26:57,226 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MapReduceLauncher - More information at: https://10.26.104.45:50030/jobdetails.jsp?jobid=job_201201021955_0002 2012-01-02 20:27:28,772 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MapReduceLauncher - 10% complete 2012-01-02 20:27:40,771 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MapReduceLauncher - 20% complete 2012-01-02 20:27:42,646 [main] INFO org.apache.hadoop.mapreduce.lib.input.FileInputFormat - Total input paths to process : 1 2012-01-02 20:27:43,209 [main] INFO org.apache.hadoop.mapred.JobClient - Running job: job_201201021955_0003 2012-01-02 20:27:44,224 [main] INFO org.apache.hadoop.mapred.JobClient - map 0% reduce 0% 2012-01-02 20:28:12,223 [main] INFO org.apache.hadoop.mapred.JobClient - map 100% reduce 0% 2012-01-02 20:28:36,223 [main] INFO org.apache.hadoop.mapred.JobClient - map 100% reduce 100% 2012-01-02 20:28:47,222 [main] INFO org.apache.hadoop.mapred.JobClient - Job complete: job_201201021955_0003 2012-01-02 20:28:47,222 [main] INFO org.apache.hadoop.mapred.JobClient - Counters: 25 2012-01-02 20:28:47,222 [main] INFO org.apache.hadoop.mapred.JobClient - Job Counters 2012-01-02 20:28:47,222 [main] INFO org.apache.hadoop.mapred.JobClient - Launched reduce tasks=1 2012-01-02 20:28:47,222 [main] INFO org.apache.hadoop.mapred.JobClient - SLOTS_MILLIS_MAPS=32061 2012-01-02 20:28:47,238 [main] INFO org.apache.hadoop.mapred.JobClient - Total time spent by all reduces waiting after reserving slots (ms)=0 2012-01-02 20:28:47,238 [main] INFO org.apache.hadoop.mapred.JobClient - Total time spent by all maps waiting after reserving slots (ms)=0 2012-01-02 20:28:47,238 [main] INFO org.apache.hadoop.mapred.JobClient - Launched map tasks=1 2012-01-02 20:28:47,238 [main] INFO org.apache.hadoop.mapred.JobClient - Data-local map tasks=1 2012-01-02 20:28:47,238 [main] INFO org.apache.hadoop.mapred.JobClient - SLOTS_MILLIS_REDUCES=21531 2012-01-02 20:28:47,238 [main] INFO org.apache.hadoop.mapred.JobClient - File Output Format Counters 2012-01-02 20:28:47,238 [main] INFO org.apache.hadoop.mapred.JobClient - Bytes Written=424066 2012-01-02 20:28:47,238 [main] INFO org.apache.hadoop.mapred.JobClient - FileSystemCounters 2012-01-02 20:28:47,238 [main] INFO org.apache.hadoop.mapred.JobClient - FILE_BYTES_READ=11850310 2012-01-02 20:28:47,238 [main] INFO org.apache.hadoop.mapred.JobClient - HDFS_BYTES_READ=3597791 2012-01-02 20:28:47,238 [main] INFO org.apache.hadoop.mapred.JobClient - FILE_BYTES_WRITTEN=17819374 2012-01-02 20:28:47,238 [main] INFO org.apache.hadoop.mapred.JobClient - HDFS_BYTES_WRITTEN=424066 2012-01-02 20:28:47,238 [main] INFO org.apache.hadoop.mapred.JobClient - File Input Format Counters 2012-01-02 20:28:47,238 [main] INFO org.apache.hadoop.mapred.JobClient - Bytes Read=3597657 2012-01-02 20:28:47,238 [main] INFO org.apache.hadoop.mapred.JobClient - Map-Reduce Framework 2012-01-02 20:28:47,238 [main] INFO org.apache.hadoop.mapred.JobClient - Reduce input groups=39491 2012-01-02 20:28:47,238 [main] INFO org.apache.hadoop.mapred.JobClient - Map output materialized bytes=5924329 2012-01-02 20:28:47,238 [main] INFO org.apache.hadoop.mapred.JobClient - Combine output records=0 2012-01-02 20:28:47,238 [main] INFO org.apache.hadoop.mapred.JobClient - Map input records=77934 2012-01-02 20:28:47,238 [main] INFO org.apache.hadoop.mapred.JobClient - Reduce shuffle bytes=0 2012-01-02 20:28:47,238 [main] INFO org.apache.hadoop.mapred.JobClient - Reduce output records=39491 2012-01-02 20:28:47,238 [main] INFO org.apache.hadoop.mapred.JobClient - Spilled Records=1890066 2012-01-02 20:28:47,238 [main] INFO org.apache.hadoop.mapred.JobClient - Map output bytes=4664279 2012-01-02 20:28:47,238 [main] INFO org.apache.hadoop.mapred.JobClient - Combine input records=0 2012-01-02 20:28:47,238 [main] INFO org.apache.hadoop.mapred.JobClient - Map output records=630022 2012-01-02 20:28:47,238 [main] INFO org.apache.hadoop.mapred.JobClient - SPLIT_RAW_BYTES=134 2012-01-02 20:28:47,238 [main] INFO org.apache.hadoop.mapred.JobClient - Reduce input records=630022 2012-01-02 20:28:47,238 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MapReduceLauncher - 40% complete 2012-01-02 20:28:47,238 [main] INFO org.apache.pig.tools.pigstats.ScriptState - Pig script settings are added to the job 2012-01-02 20:28:47,238 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.JobControlCompiler - mapred.job.reduce.markreset.buffer.percent is not set, set to default 0.3 2012-01-02 20:28:48,629 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.JobControlCompiler - Setting up single store job 2012-01-02 20:28:48,644 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MapReduceLauncher - 1 map-reduce job(s) waiting for submission. 2012-01-02 20:28:49,035 [Thread-24] INFO org.apache.hadoop.mapreduce.lib.input.FileInputFormat - Total input paths to process : 1 2012-01-02 20:28:49,035 [Thread-24] INFO org.apache.pig.backend.hadoop.executionengine.util.MapRedUtil - Total input paths to process : 1 2012-01-02 20:28:49,035 [Thread-24] INFO org.apache.pig.backend.hadoop.executionengine.util.MapRedUtil - Total input paths (combined) to process : 1 2012-01-02 20:28:50,050 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MapReduceLauncher - HadoopJobId: job_201201021955_0004 2012-01-02 20:28:50,050 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MapReduceLauncher - More information at: https://10.26.104.45:50030/jobdetails.jsp?jobid=job_201201021955_0004 2012-01-02 20:29:17,550 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MapReduceLauncher - 50% complete 2012-01-02 20:29:20,049 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MapReduceLauncher - 50% complete 2012-01-02 20:29:25,049 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MapReduceLauncher - 50% complete 2012-01-02 20:29:29,549 [main] INFO org.apache.pig.tools.pigstats.ScriptState - Pig script settings are added to the job 2012-01-02 20:29:29,549 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.JobControlCompiler - mapred.job.reduce.markreset.buffer.percent is not set, set to default 0.3 2012-01-02 20:29:30,768 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.JobControlCompiler - Setting up single store job 2012-01-02 20:29:30,830 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MapReduceLauncher - 1 map-reduce job(s) waiting for submission. 2012-01-02 20:29:31,205 [Thread-34] INFO org.apache.hadoop.mapreduce.lib.input.FileInputFormat - Total input paths to process : 1 2012-01-02 20:29:31,205 [Thread-34] INFO org.apache.pig.backend.hadoop.executionengine.util.MapRedUtil - Total input paths to process : 1 2012-01-02 20:29:31,205 [Thread-34] INFO org.apache.pig.backend.hadoop.executionengine.util.MapRedUtil - Total input paths (combined) to process : 1 2012-01-02 20:29:31,330 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MapReduceLauncher - 60% complete 2012-01-02 20:29:32,252 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MapReduceLauncher - HadoopJobId: job_201201021955_0005 2012-01-02 20:29:32,252 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MapReduceLauncher - More information at: https://10.26.104.45:50030/jobdetails.jsp?jobid=job_201201021955_0005 2012-01-02 20:30:11,251 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MapReduceLauncher - 70% complete 2012-01-02 20:30:12,251 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MapReduceLauncher - 70% complete 2012-01-02 20:30:17,251 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MapReduceLauncher - 70% complete 2012-01-02 20:30:22,251 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MapReduceLauncher - 70% complete 2012-01-02 20:30:27,250 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MapReduceLauncher - 70% complete 2012-01-02 20:30:32,750 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MapReduceLauncher - 80% complete 2012-01-02 20:30:37,250 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MapReduceLauncher - 80% complete 2012-01-02 20:30:42,250 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MapReduceLauncher - 80% complete 2012-01-02 20:30:46,765 [main] INFO org.apache.pig.tools.pigstats.ScriptState - Pig script settings are added to the job 2012-01-02 20:30:46,765 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.JobControlCompiler - mapred.job.reduce.markreset.buffer.percent is not set, set to default 0.3 2012-01-02 20:30:47,937 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.JobControlCompiler - Setting up single store job 2012-01-02 20:30:47,984 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MapReduceLauncher - 1 map-reduce job(s) waiting for submission. 2012-01-02 20:30:48,406 [Thread-45] INFO org.apache.hadoop.mapreduce.lib.input.FileInputFormat - Total input paths to process : 1 2012-01-02 20:30:48,406 [Thread-45] INFO org.apache.pig.backend.hadoop.executionengine.util.MapRedUtil - Total input paths to process : 1 2012-01-02 20:30:48,406 [Thread-45] INFO org.apache.pig.backend.hadoop.executionengine.util.MapRedUtil - Total input paths (combined) to process : 1 2012-01-02 20:30:48,484 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MapReduceLauncher - 80% complete 2012-01-02 20:30:49,390 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MapReduceLauncher - HadoopJobId: job_201201021955_0006 2012-01-02 20:30:49,390 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MapReduceLauncher - More information at: https://10.26.104.45:50030/jobdetails.jsp?jobid=job_201201021955_0006 2012-01-02 20:31:17,889 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MapReduceLauncher - 90% complete 2012-01-02 20:31:19,389 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MapReduceLauncher - 90% complete 2012-01-02 20:31:24,389 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MapReduceLauncher - 90% complete 2012-01-02 20:31:34,389 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MapReduceLauncher - 90% complete 2012-01-02 20:31:48,982 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MapReduceLauncher - 100% complete 2012-01-02 20:31:48,998 [main] INFO org.apache.pig.tools.pigstats.PigStats - Script Statistics:
HadoopVersion PigVersion UserId StartedAt FinishedAt Features 0.20.203.1-SNAPSHOT 0.8.1-SNAPSHOT avkash 2012-01-02 20:26:53 2012-01-02 20:31:48 ORDER_BY,LIMIT,NATIVE
Success!
Job Stats (time in seconds): JobId Maps Reduces MaxMapTime MinMapTIme AvgMapTime MaxReduceTime MinReduceTime AvgReduceTime Alias Feature Outputs job_201201021955_0002 1 0 15 15 15 0 0 0 q0 MAP_ONLY job_201201021955_0004 1 0 12 12 12 0 0 0 q1 MAP_ONLY job_201201021955_0005 1 1 11 11 11 21 21 21 q2 SAMPLER job_201201021955_0006 1 1 12 12 12 18 18 18 q2 ORDER_BY,COMBINER hdfs://10.26.104.45:9000/user/avkash/top15words, job_D:/Users/avkash/AppData/Local/Temp/MRjs1699097122276446870.jar__0001 0 0 0 0 0 0 0 0 NATIVE
Input(s): Successfully read 77934 records (3644014 bytes) from: "hdfs://10.26.104.45:9000/user/avkash/wordsfolder" Successfully read 39491 records (424454 bytes) from: "hdfs://10.26.104.45:9000/user/avkash/.oink/output2/mr/out"
Output(s): Successfully stored 15 records (132 bytes) in: "hdfs://10.26.104.45:9000/user/avkash/top15words"
Counters: Total records written : 15 Total bytes written : 132 Spillable Memory Manager spill count : 0 Total bags proactively spilled: 0 Total records proactively spilled: 0
Job DAG: job_201201021955_0002 -> job_D:/Users/avkash/AppData/Local/Temp/MRjs1699097122276446870.jar__0001, job_D:/Users/avkash/AppData/Local/Temp/MRjs1699097122276446870.jar__0001 -> job_201201021955_0004, job_201201021955_0004 -> job_201201021955_0005, job_201201021955_0005 -> job_201201021955_0006, job_201201021955_0006
2012-01-02 20:31:49,092 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MapReduceLauncher - Success! |
Keywords: Windows Azure, Hadoop, Apache, BigData, Cloud, MapReduce