Apache Hadoop on Windows Azure Part 8 – Hadoop Map/Reduce Administration from command line in Cluster
After you created your Hadoop cluster in Windows Azure, you can remote into it to start the Map/Reduce administration. Most of the processing log & HDFS data is already available over port 50030 and 50070 however, you can run bunch of standard Hadoop commands directly from command line.
After you login to your main node, you will see Hadoop Command Shell shortcut is already there which launches the command as below:
D:\Windows\System32\cmd.exe /k c:\apps\dist\bin\hadoop.cmd
Once you start the Hadoop Shell shortcut you will see the list of commands you can use as below:
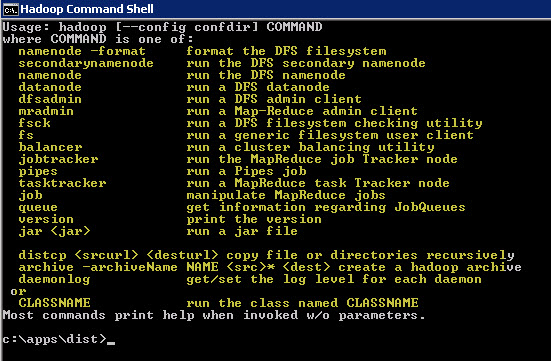
For example you can check the name node details by using “Hadoop namenode” command:
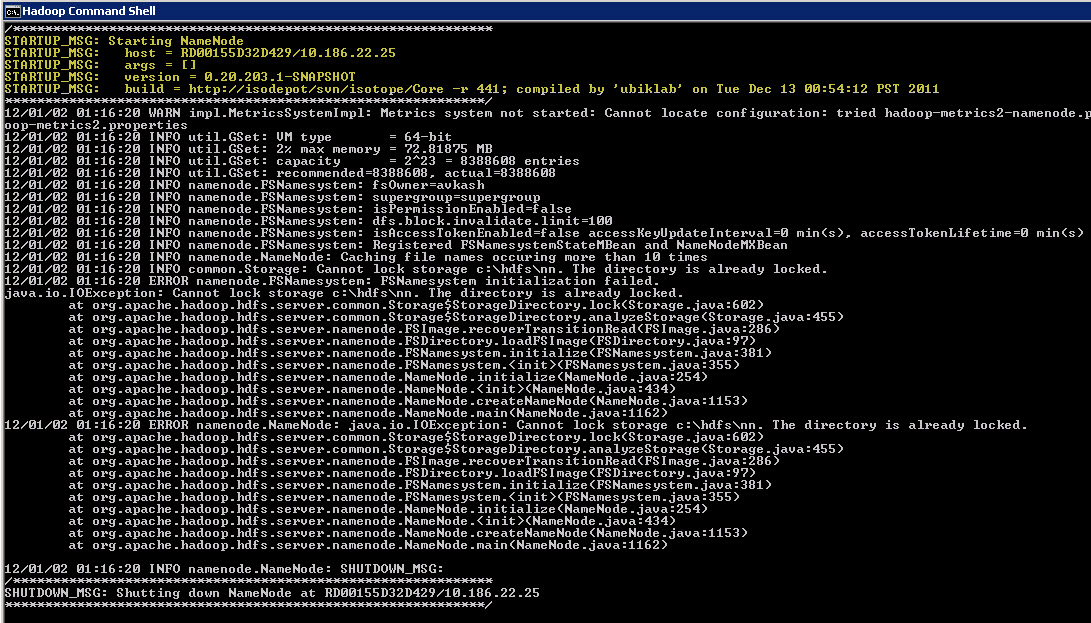
If you want to start a datanode you just run “Hadoop datanode” command:

Now let’s check if any jobs are running using command “hadoop job –list”
c:\apps\dist>hadoop job -list
0 jobs currently running
JobId State StartTime UserName Priority SchedulingInfo
Now let me start a Hadoop Job and then we will check the job list again:
c:\apps\dist>hadoop job -list
1 jobs currently running
JobId State StartTime UserName Priority SchedulingInfo
job_201112310614_0004 4 1325469341874 avkash NORMAL NA
c:\apps\dist>hadoop job -status job_201112310614_0004
Job: job_201112310614_0004
file: hdfs://10.186.22.25:9000/hdfs/tmp/mapred/staging/avkash/.staging/job_201112310614_0004/job.xml
tracking URL: https://10.186.22.25:50030/jobdetails.jsp?jobid=job\_201112310614\_0004
map() completion: 1.0
reduce() completion: 1.0
Counters: 23
Job Counters
Launched reduce tasks=1
SLOTS_MILLIS_MAPS=19420
Launched map tasks=1
Data-local map tasks=1
SLOTS_MILLIS_REDUCES=15591
File Output Format Counters
Bytes Written=123
FileSystemCounters
FILE_BYTES_READ=579
HDFS_BYTES_READ=234
FILE_BYTES_WRITTEN=43645
HDFS_BYTES_WRITTEN=123
File Input Format Counters
Bytes Read=108
Map-Reduce Framework
Reduce input groups=7
Map output materialized bytes=189
Combine output records=15
Map input records=15
Reduce shuffle bytes=0
Reduce output records=15
Spilled Records=30
Map output bytes=153
Combine input records=15
Map output records=15
SPLIT_RAW_BYTES=126
Reduce input records=15
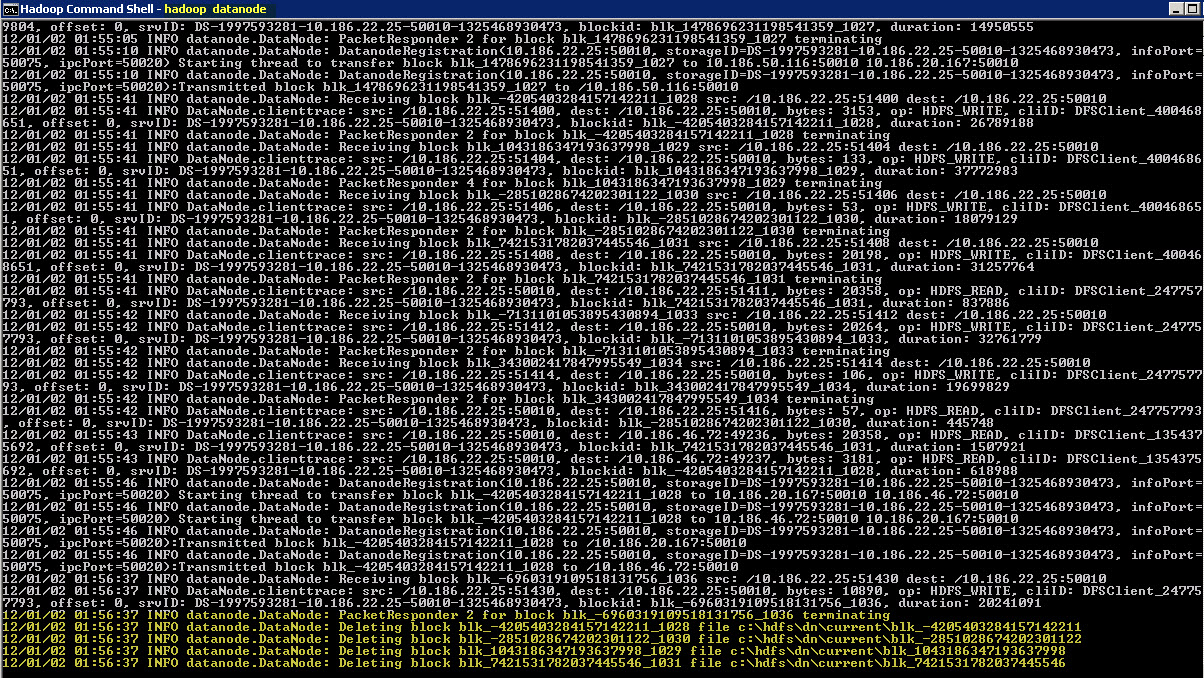
As a new job has been started you will also see data coming out at datanode windows as well:
Keywords: Windows Azure, Hadoop, Apache, BigData, Cloud, MapReduce