Apache Hadoop on Windows Azure Part 7 – Writing your very own WordCount Hadoop Job in Java and deploying to Windows Azure Cluster
In this article, I will help you writing your own WordCount Hadoop Job and then deploy it to Windows Azure Cluster for further processing.
Let’s create Java code file as “AvkashWordCount.java” as below:
package org.myorg; import java.io.IOException; import java.util.*; import org.apache.hadoop.fs.Path; import org.apache.hadoop.conf.*; import org.apache.hadoop.io.*; import org.apache.hadoop.util.*; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.conf.Configured; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class AvkashWordCount { public static class Map extends Mapper <LongWritable, Text, Text, IntWritable> { private final static IntWritable one = new IntWritable(1); private Text word = new Text();
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String line = value.toString(); StringTokenizer tokenizer = new StringTokenizer(line); while (tokenizer.hasMoreTokens()) { word.set(tokenizer.nextToken()); context.write(word, one); } } } public static class Reduce extends Reducer <Text, IntWritable, Text, IntWritable> { public void reduce(Text key, Iterator<IntWritable> values, Context context) throws IOException, InterruptedException { int sum = 0; while (values.hasNext()) { sum += values.next().get(); } context.write(key, new IntWritable(sum)); } } public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); Job job = new Job(conf); job.setJarByClass(AvkashWordCount.class); job.setJobName("avkashwordcountjob"); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); job.setMapperClass(AvkashWordCount.Map.class); job.setCombinerClass(AvkashWordCount.Reduce.class); job.setReducerClass(AvkashWordCount.Reduce.class); FileInputFormat.addInputPath(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); job.waitForCompletion(true); } } |
Let’s Compile the Java code first. You must have Hadoop 0.20 or above installed in your machined to use this code:
C:\Azure\Java>C:\Apps\java\openjdk7\bin\javac -classpath c:\Apps\dist\hadoop-core-0.20.203.1-SNAPSHOT.jar -d . AvkashWordCount.java
Now let’s crate the JAR file
C:\Azure\Java>C:\Apps\java\openjdk7\bin\jar -cvf AvkashWordCount.jar org
added manifest
adding: org/(in = 0) (out= 0)(stored 0%)
adding: org/myorg/(in = 0) (out= 0)(stored 0%)
adding: org/myorg/AvkashWordCount$Map.class(in = 1893) (out= 792)(deflated 58%)
adding: org/myorg/AvkashWordCount$Reduce.class(in = 1378) (out= 596)(deflated 56%)
adding: org/myorg/AvkashWordCount.class(in = 1399) (out= 754)(deflated 46%)
Once Jar is created please deploy it to your Windows Azure Hadoop Cluster as below:

In the page below please follow all the steps as described below:
- Step 1: Click Browse to select your "AvkashWordCount.Jar" file here
- Step 2: Enter the Job name as defined in the source code
- Step 3: Add the parameter as below
- Step 4: Add folder name where files will be read to word count
- Step 5: Add output folder name where the results will be stored
- Step 6: Start the Job
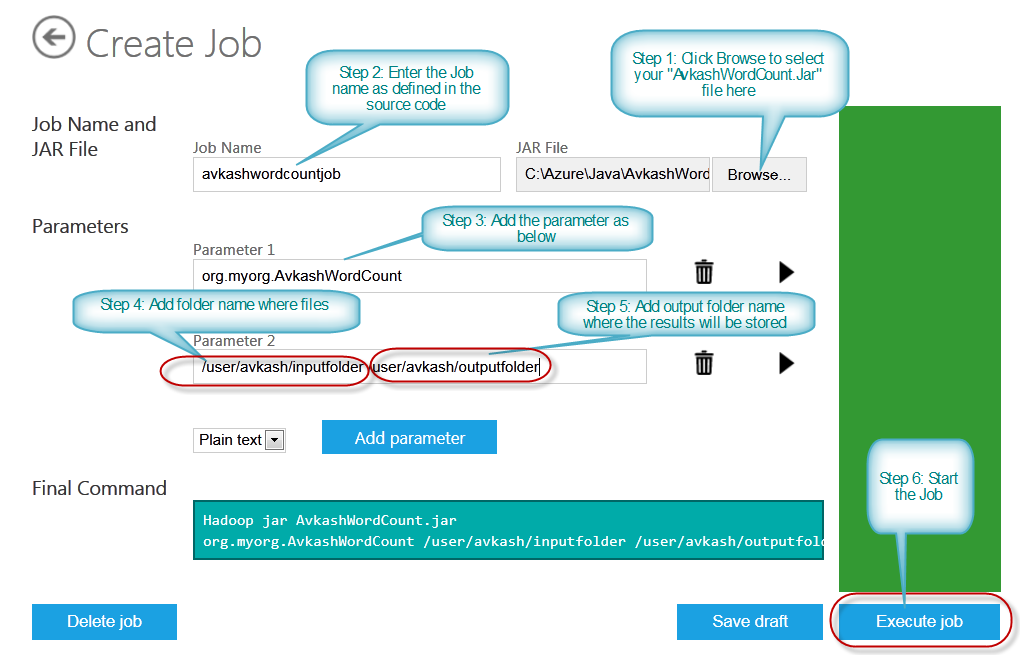
Note: Be sure to have some data in your input folder. (Avkash I am using /user/avkash/inputfolder which has a text file with lots of word to be used as Word Count input file)
Once the job is stared, you will see the results as below:
|
••• Job Info Status: Completed Sucessfully Type: jar Start time: 12/31/2011 4:06:51 PM End time: 12/31/2011 4:07:53 PM Exit code: 0 Command call hadoop.cmd jar AvkashWordCount.jar org.myorg.AvkashWordCount /user/avkash/inputfolder /user/avkash/outputfolder Output (stdout)
Errors (stderr) 11/12/31 16:06:53 INFO input.FileInputFormat: Total input paths to process : 1 11/12/31 16:06:54 INFO mapred.JobClient: Running job: job_201112310614_0001 11/12/31 16:06:55 INFO mapred.JobClient: map 0% reduce 0% 11/12/31 16:07:20 INFO mapred.JobClient: map 100% reduce 0% 11/12/31 16:07:42 INFO mapred.JobClient: map 100% reduce 100% 11/12/31 16:07:53 INFO mapred.JobClient: Job complete: job_201112310614_0001 11/12/31 16:07:53 INFO mapred.JobClient: Counters: 25 11/12/31 16:07:53 INFO mapred.JobClient: Job Counters 11/12/31 16:07:53 INFO mapred.JobClient: Launched reduce tasks=1 11/12/31 16:07:53 INFO mapred.JobClient: SLOTS_MILLIS_MAPS=29029 11/12/31 16:07:53 INFO mapred.JobClient: Total time spent by all reduces waiting after reserving slots (ms)=0 11/12/31 16:07:53 INFO mapred.JobClient: Total time spent by all maps waiting after reserving slots (ms)=0 11/12/31 16:07:53 INFO mapred.JobClient: Launched map tasks=1 11/12/31 16:07:53 INFO mapred.JobClient: Data-local map tasks=1 11/12/31 16:07:53 INFO mapred.JobClient: SLOTS_MILLIS_REDUCES=18764 11/12/31 16:07:53 INFO mapred.JobClient: File Output Format Counters 11/12/31 16:07:53 INFO mapred.JobClient: Bytes Written=123 11/12/31 16:07:53 INFO mapred.JobClient: FileSystemCounters 11/12/31 16:07:53 INFO mapred.JobClient: FILE_BYTES_READ=709 11/12/31 16:07:53 INFO mapred.JobClient: HDFS_BYTES_READ=234 11/12/31 16:07:53 INFO mapred.JobClient: FILE_BYTES_WRITTEN=43709 11/12/31 16:07:53 INFO mapred.JobClient: HDFS_BYTES_WRITTEN=123 11/12/31 16:07:53 INFO mapred.JobClient: File Input Format Counters 11/12/31 16:07:53 INFO mapred.JobClient: Bytes Read=108 11/12/31 16:07:53 INFO mapred.JobClient: Map-Reduce Framework 11/12/31 16:07:53 INFO mapred.JobClient: Reduce input groups=7 11/12/31 16:07:53 INFO mapred.JobClient: Map output materialized bytes=189 11/12/31 16:07:53 INFO mapred.JobClient: Combine output records=15 11/12/31 16:07:53 INFO mapred.JobClient: Map input records=15 11/12/31 16:07:53 INFO mapred.JobClient: Reduce shuffle bytes=0 11/12/31 16:07:53 INFO mapred.JobClient: Reduce output records=15 11/12/31 16:07:53 INFO mapred.JobClient: Spilled Records=30 11/12/31 16:07:53 INFO mapred.JobClient: Map output bytes=153 11/12/31 16:07:53 INFO mapred.JobClient: Combine input records=15 11/12/31 16:07:53 INFO mapred.JobClient: Map output records=15 11/12/31 16:07:53 INFO mapred.JobClient: SPLIT_RAW_BYTES=126 11/12/31 16:07:53 INFO mapred.JobClient: Reduce input records=15
|
Finally you can open output folder /user/avkash/outputfolder and read the Word Count results.
Keywords: Windows Azure, Hadoop, Apache, BigData, Cloud, MapReduce