Apache Hadoop on Windows Azure Part 6 - Running 10GB Sort Hadoop Job with TeraSort Option and understanding MapReduce Job administration
In this section we will run the same 10GB sorting Hadoop job with TERASORT option. With TeraSort option the parameters are changed as below:
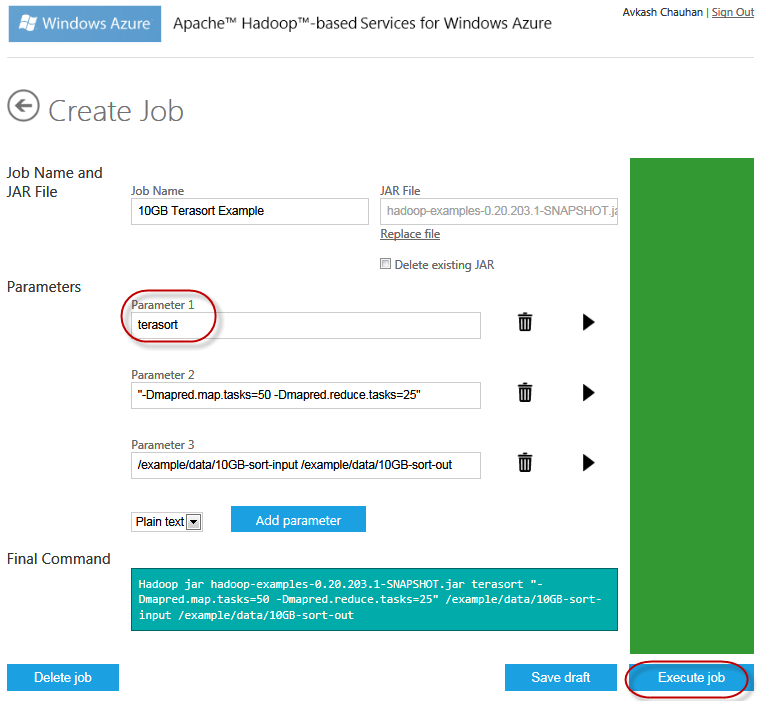
With above parameters couple of things to remember:
- You must have /example/data/10GB-sort-input folder along with data (This is created when you use teragen option first as explained in Exercise 5)
- You also need to have
Once you start the job you will see the reads data from the /example/data/10GB-sort-input folder
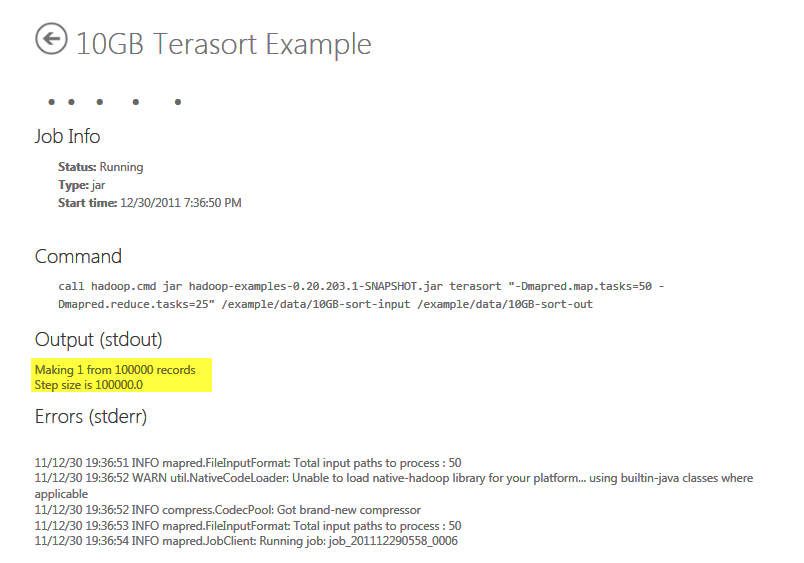
Now you can login to your cluster using your RD credentials and launch local IP with port 50030 for node administration as below:
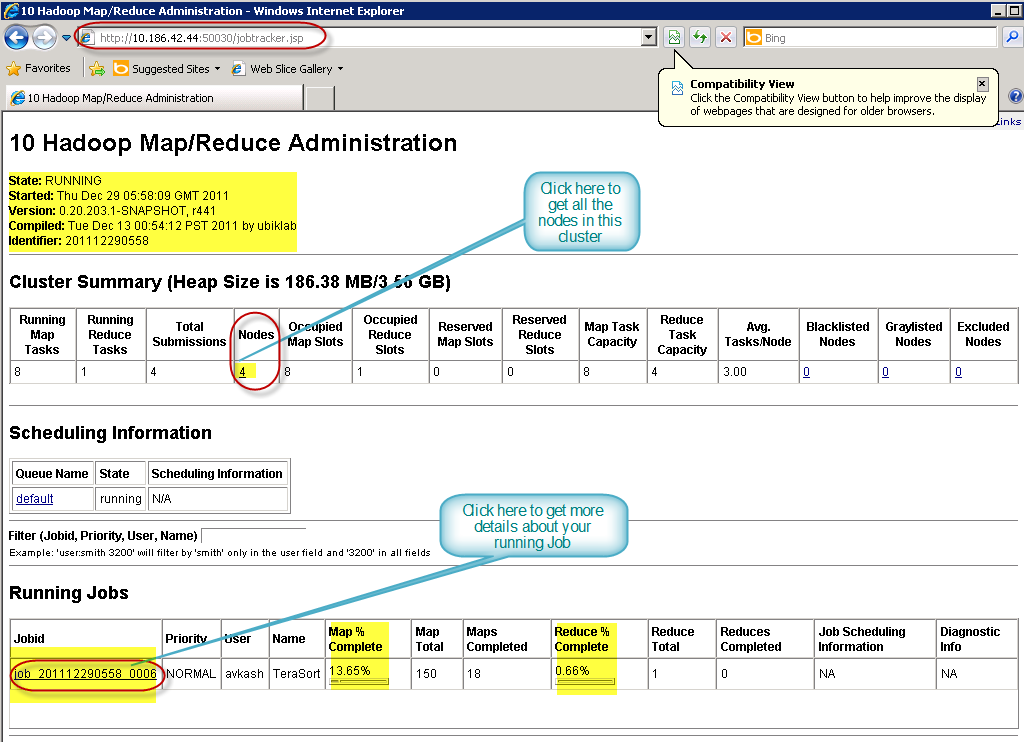
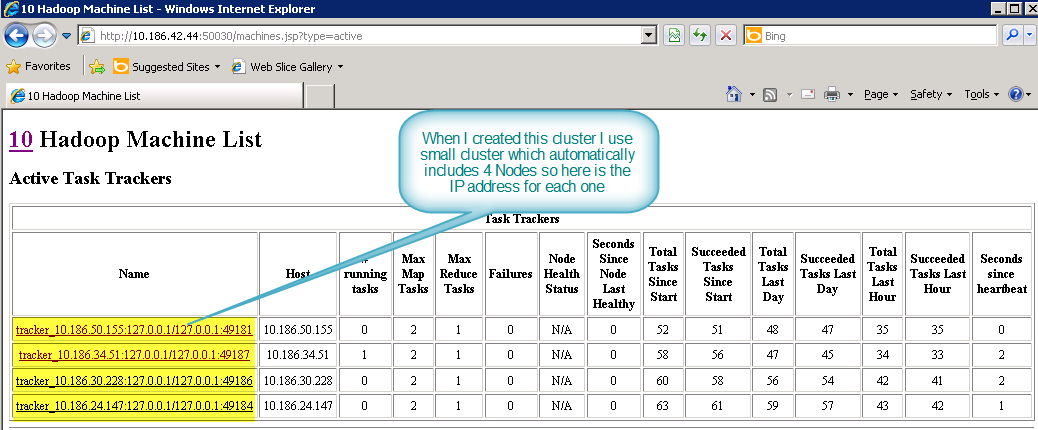
Above if you want to know how many nodes I have you would need to click “Nodes” section in the cluster Summary table to find each node details and its IP Address:
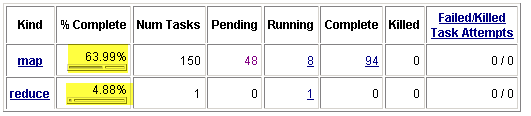
In the Map/Reduce Administration page, once you click on the running job, you can get further details about your job progress as below:
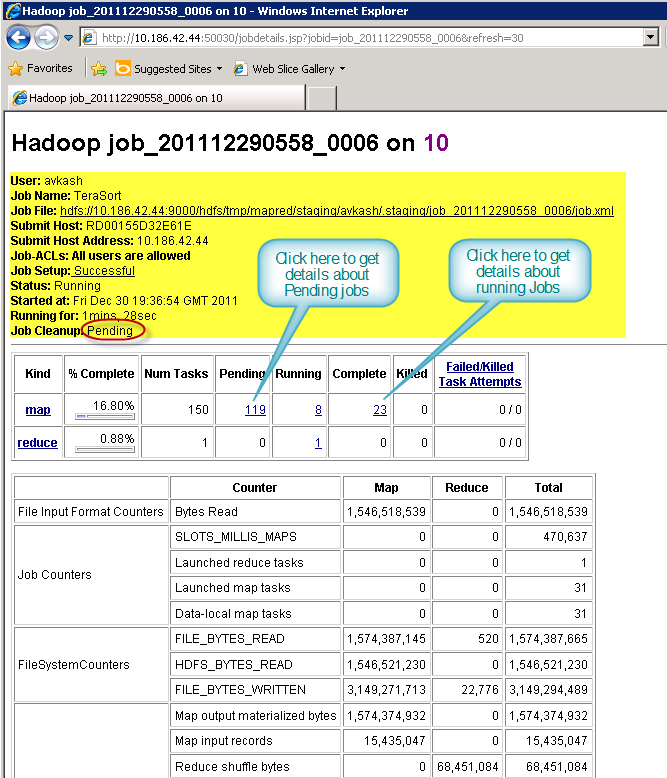
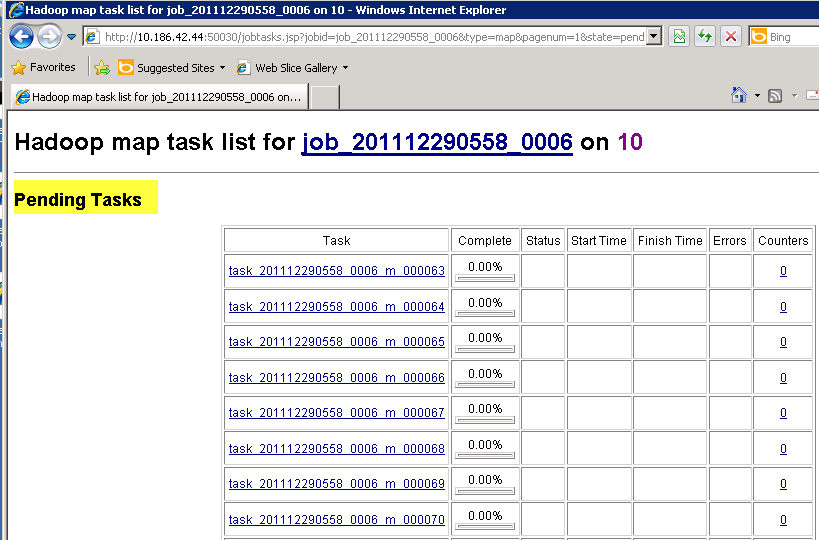
If you want to further dig into individual pending/running or completed job just click on either Map or Reduce tasks counter above and you will see details as below:
Pending Tasks:
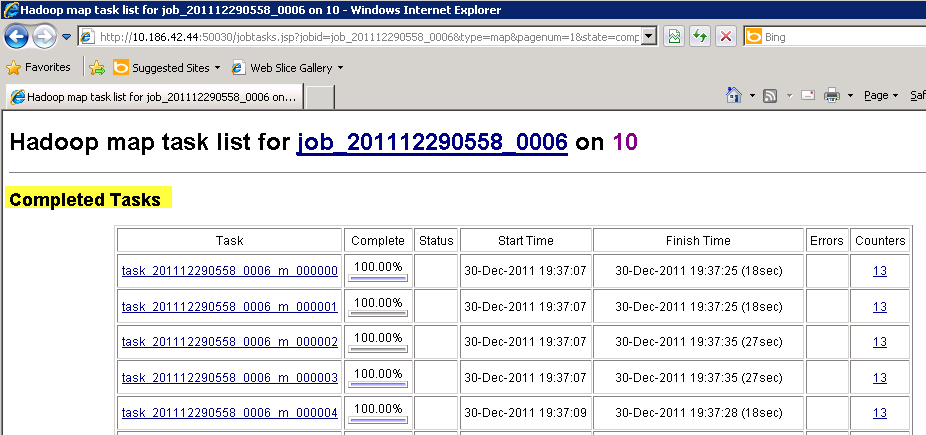
Completed Tasks:
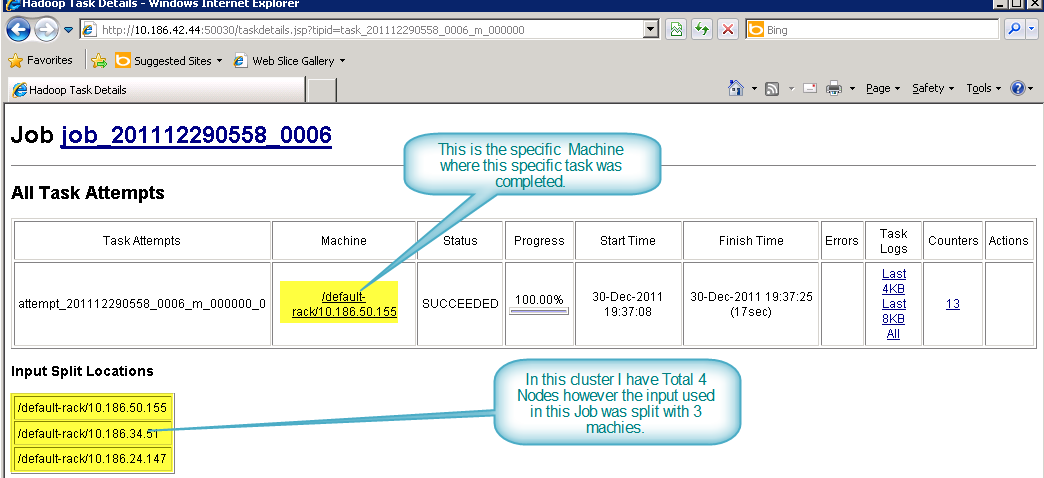
Now if you select a completed task and open for more info you will see:
When your Job is running you can also visualize the Map/Reduce process either at Hadoop on Azure Portal or directly in your Node Admin section inside the cluster as below:
Job Progress at Hadoop on Azure Portal:
11/12/30 19:41:45 INFO mapred.JobClient: map 57% reduce 4% 11/12/30 19:41:57 INFO mapred.JobClient: map 59% reduce 4% 11/12/30 19:42:06 INFO mapred.JobClient: map 60% reduce 4% 11/12/30 19:42:07 INFO mapred.JobClient: map 61% reduce 4% 11/12/30 19:42:15 INFO mapred.JobClient: map 62% reduce 4% 11/12/30 19:42:18 INFO mapred.JobClient: map 63% reduce 4% 11/12/30 19:42:21 INFO mapred.JobClient: map 64% reduce 4% |
Job Progress directly seen inside the cluster directly at https://10.186.42.44:50030/jobdetails.jsp?jobid=job_201112290558_0006&refresh=30
Finally Job will be completed when both Map and Reduce jobs are 100% completed
10GB Terasort ExampleJob InfoStatus: Completed Successfully Type: jar Start time: 12/30/2011 7:36:50 PM End time: 12/30/2011 8:48:36 PM Exit code: 0 Commandcall hadoop.cmd jar hadoop-examples-0.20.203.1-SNAPSHOT.jar terasort "-Dmapred.map.tasks=50 -Dmapred.reduce.tasks=25" /example/data/10GB-sort-input /example/data/10GB-sort-out Output (stdout)Making 1 from 100000 records Step size is 100000.0 Errors (stderr)11/12/30 19:36:51 INFO terasort.TeraSort: starting 11/12/30 19:36:51 INFO mapred.FileInputFormat: Total input paths to process : 50 11/12/30 19:36:52 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable 11/12/30 19:36:52 INFO compress.CodecPool: Got brand-new compressor 11/12/30 19:36:53 INFO mapred.FileInputFormat: Total input paths to process : 50 11/12/30 19:36:54 INFO mapred.JobClient: Running job: job_201112290558_0006 11/12/30 19:36:55 INFO mapred.JobClient: map 0% reduce 0% 11/12/30 19:37:24 INFO mapred.JobClient: map 2% reduce 0% 11/12/30 19:37:26 INFO mapred.JobClient: map 5% reduce 0% 11/12/30 19:37:44 INFO mapred.JobClient: map 7% reduce 0% 11/12/30 19:37:48 INFO mapred.JobClient: map 8% reduce 0% 11/12/30 19:37:50 INFO mapred.JobClient: map 9% reduce 0% 11/12/30 19:37:52 INFO mapred.JobClient: map 10% reduce 0% …… …… 11/12/30 20:47:24 INFO mapred.JobClient: map 100% reduce 98% 11/12/30 20:47:51 INFO mapred.JobClient: map 100% reduce 99% 11/12/30 20:48:21 INFO mapred.JobClient: map 100% reduce 100% 11/12/30 20:48:35 INFO mapred.JobClient: Job complete: job_201112290558_0006 11/12/30 20:48:35 INFO mapred.JobClient: Counters: 27 11/12/30 20:48:35 INFO mapred.JobClient: Job Counters 11/12/30 20:48:35 INFO mapred.JobClient: Launched reduce tasks=1 11/12/30 20:48:35 INFO mapred.JobClient: SLOTS_MILLIS_MAPS=3766703 11/12/30 20:48:35 INFO mapred.JobClient: Total time spent by all reduces waiting after reserving slots (ms)=0 11/12/30 20:48:35 INFO mapred.JobClient: Total time spent by all maps waiting after reserving slots (ms)=0 11/12/30 20:48:35 INFO mapred.JobClient: Rack-local map tasks=1 11/12/30 20:48:35 INFO mapred.JobClient: Launched map tasks=153 11/12/30 20:48:35 INFO mapred.JobClient: Data-local map tasks=152 11/12/30 20:48:35 INFO mapred.JobClient: SLOTS_MILLIS_REDUCES=4244002 11/12/30 20:48:35 INFO mapred.JobClient: File Input Format Counters 11/12/30 20:48:35 INFO mapred.JobClient: Bytes Read=10013107300 11/12/30 20:48:35 INFO mapred.JobClient: File Output Format Counters 11/12/30 20:48:35 INFO mapred.JobClient: Bytes Written=10000000000 11/12/30 20:48:35 INFO mapred.JobClient: FileSystemCounters 11/12/30 20:48:35 INFO mapred.JobClient: FILE_BYTES_READ=26766944216 11/12/30 20:48:35 INFO mapred.JobClient: HDFS_BYTES_READ=10013124850 11/12/30 20:48:35 INFO mapred.JobClient: FILE_BYTES_WRITTEN=36970291186 11/12/30 20:48:35 INFO mapred.JobClient: HDFS_BYTES_WRITTEN=10000000000 11/12/30 20:48:35 INFO mapred.JobClient: Map-Reduce Framework 11/12/30 20:48:35 INFO mapred.JobClient: Map output materialized bytes=10200000900 11/12/30 20:48:35 INFO mapred.JobClient: Map input records=100000000 11/12/30 20:48:35 INFO mapred.JobClient: Reduce shuffle bytes=10132903050 11/12/30 20:48:35 INFO mapred.JobClient: Spilled Records=362419016 11/12/30 20:48:35 INFO mapred.JobClient: Map output bytes=10000000000 11/12/30 20:48:35 INFO mapred.JobClient: Map input bytes=10000000000 11/12/30 20:48:35 INFO mapred.JobClient: Combine input records=0 11/12/30 20:48:35 INFO mapred.JobClient: SPLIT_RAW_BYTES=17550 11/12/30 20:48:35 INFO mapred.JobClient: Reduce input records=100000000 11/12/30 20:48:35 INFO mapred.JobClient: Reduce input groups=100000000 11/12/30 20:48:35 INFO mapred.JobClient: Combine output records=0 11/12/30 20:48:35 INFO mapred.JobClient: Reduce output records=100000000 11/12/30 20:48:35 INFO mapred.JobClient: Map output records=100000000 11/12/30 20:48:35 INFO terasort.TeraSort: done |
Keywords: Windows Azure, Hadoop, Apache, BigData, Cloud, MapReduce