Apache Hadoop on Windows Azure Part 3 - Creating a Word Count Hadoop Job with a few twists
In this example I am starting a new Hadoop Job with few intentional errors to understand the processing better. You can go to Samples and deploy the Wordcount sample job to your cluster. Verify all the parameters and then you can start the job as below:
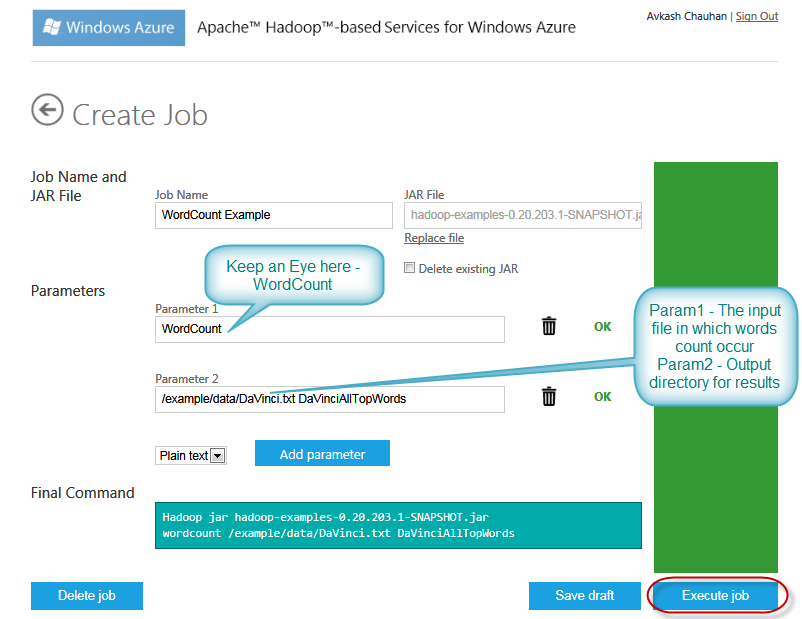
Note: There are to error in above steps:
- Intensely I haven’t uploaded the davinci.txt file to the cluster yet
- I have given the wrong parameter
Once the Job will start very soon you will hit this error:
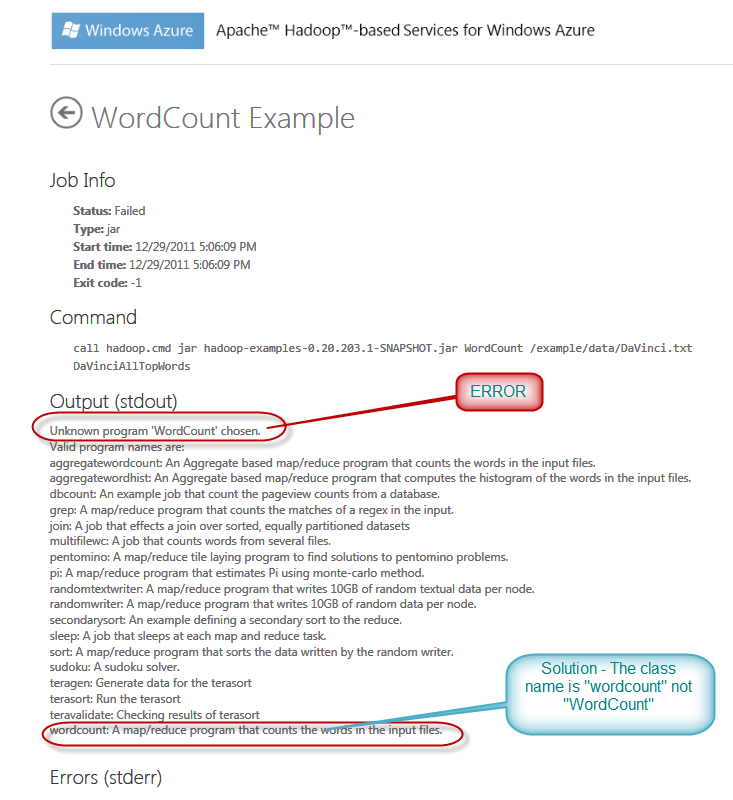
As you can see above the class name was wrong which resulted into an error. Now you can change the correct parameter name as “wordcount” and restart the job.
Now you will hit another error as below:
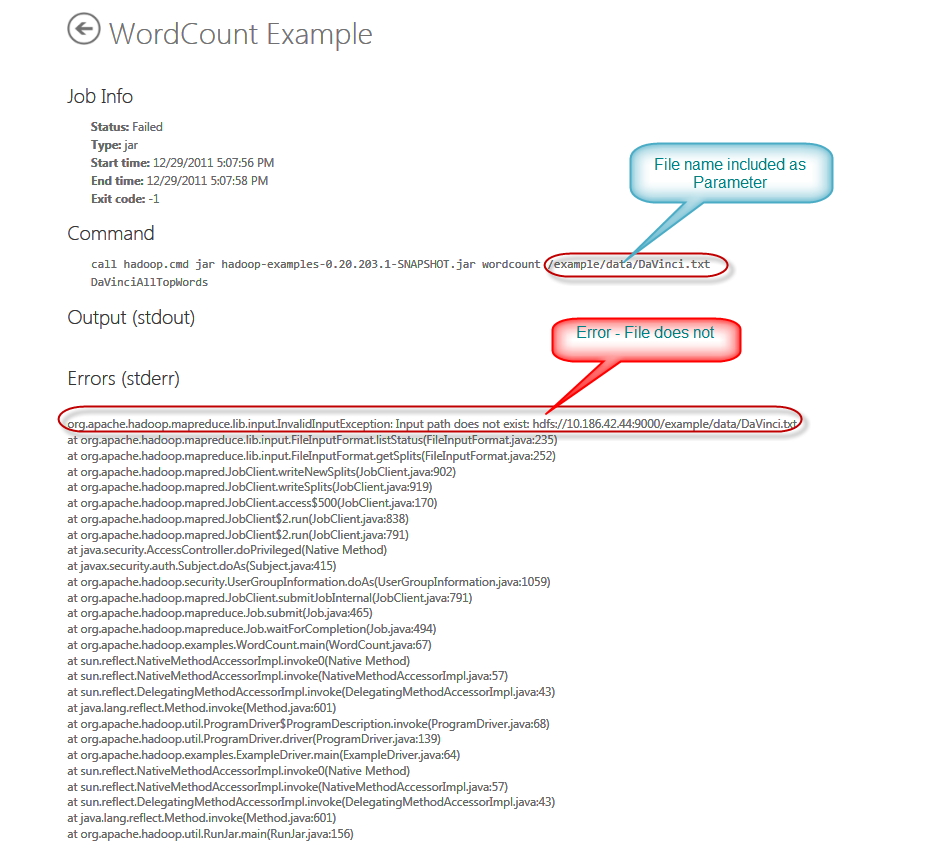
To solve this problem lets upload the txt file name davinci.txt to cluster. (Please see the wordcount sample page for more info about this step)
To upload the file, we will launch Interactive JavaScript console as below:
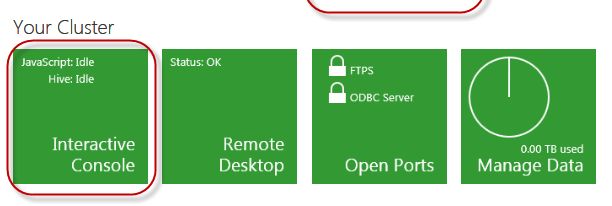
When Interactive JavaScript console is open you can use fs.put() command to select the txt file from local machine and upload to desired folder at HDFS file system in cluster.
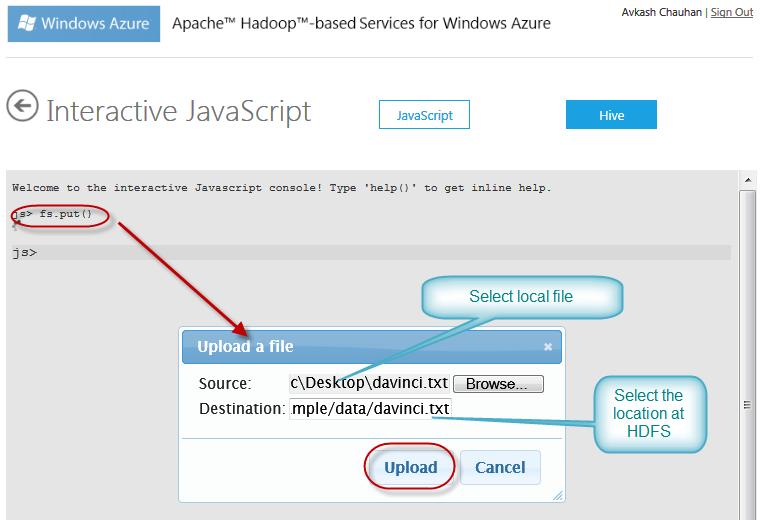
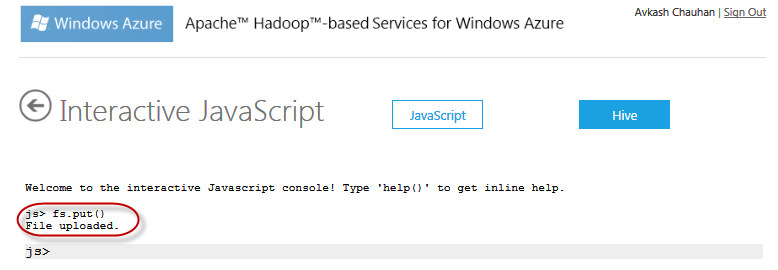
Once file upload is completed you will get the result message:
Let’s run the job again and now you will see the expected results as below. To solve this problem you just need to pass the second parameter with new output directory name.
WordCount Example Job Info Status: Completed Successfully Type: jar Start time: 12/29/2011 5:33:00 PM End time: 12/29/2011 5:33:58 PM Exit code: 0 Command call hadoop.cmd jar hadoop-examples-0.20.203.1-SNAPSHOT.jar wordcount /example/data/davinci.txt DaVinciAllTopWords Output (stdout)
Errors (stderr) 11/12/29 17:33:02 INFO input.FileInputFormat: Total input paths to process : 1 11/12/29 17:33:03 INFO mapred.JobClient: Running job: job_201112290558_0003 11/12/29 17:33:04 INFO mapred.JobClient: map 0% reduce 0% 11/12/29 17:33:29 INFO mapred.JobClient: map 100% reduce 0% 11/12/29 17:33:47 INFO mapred.JobClient: map 100% reduce 100% 11/12/29 17:33:58 INFO mapred.JobClient: Job complete: job_201112290558_0003 11/12/29 17:33:58 INFO mapred.JobClient: Counters: 25 11/12/29 17:33:58 INFO mapred.JobClient: Job Counters 11/12/29 17:33:58 INFO mapred.JobClient: Launched reduce tasks=1 11/12/29 17:33:58 INFO mapred.JobClient: SLOTS_MILLIS_MAPS=29185 11/12/29 17:33:58 INFO mapred.JobClient: Total time spent by all reduces waiting after reserving slots (ms)=0 11/12/29 17:33:58 INFO mapred.JobClient: Total time spent by all maps waiting after reserving slots (ms)=0 11/12/29 17:33:58 INFO mapred.JobClient: Rack-local map tasks=1 11/12/29 17:33:58 INFO mapred.JobClient: Launched map tasks=1 11/12/29 17:33:58 INFO mapred.JobClient: SLOTS_MILLIS_REDUCES=15671 11/12/29 17:33:58 INFO mapred.JobClient: File Output Format Counters 11/12/29 17:33:58 INFO mapred.JobClient: Bytes Written=337623 11/12/29 17:33:58 INFO mapred.JobClient: FileSystemCounters 11/12/29 17:33:58 INFO mapred.JobClient: FILE_BYTES_READ=467151 11/12/29 17:33:58 INFO mapred.JobClient: HDFS_BYTES_READ=1427899 11/12/29 17:33:58 INFO mapred.JobClient: FILE_BYTES_WRITTEN=977063 11/12/29 17:33:58 INFO mapred.JobClient: HDFS_BYTES_WRITTEN=337623 11/12/29 17:33:58 INFO mapred.JobClient: File Input Format Counters 11/12/29 17:33:58 INFO mapred.JobClient: Bytes Read=1427785 11/12/29 17:33:58 INFO mapred.JobClient: Map-Reduce Framework 11/12/29 17:33:58 INFO mapred.JobClient: Reduce input groups=32956 11/12/29 17:33:58 INFO mapred.JobClient: Map output materialized bytes=466761 11/12/29 17:33:58 INFO mapred.JobClient: Combine output records=32956 11/12/29 17:33:58 INFO mapred.JobClient: Map input records=32118 11/12/29 17:33:58 INFO mapred.JobClient: Reduce shuffle bytes=466761 11/12/29 17:33:58 INFO mapred.JobClient: Reduce output records=32956 11/12/29 17:33:58 INFO mapred.JobClient: Spilled Records=65912 11/12/29 17:33:58 INFO mapred.JobClient: Map output bytes=2387798 11/12/29 17:33:58 INFO mapred.JobClient: Combine input records=251357 11/12/29 17:33:58 INFO mapred.JobClient: Map output records=251357 11/12/29 17:33:58 INFO mapred.JobClient: SPLIT_RAW_BYTES=114 11/12/29 17:33:58 INFO mapred.JobClient: Reduce input records=32956 |
If you run the same Job again you will see the following results:
WordCount Example••••• Job InfoStatus: Failed Type: jar Start time: 12/29/2011 5:46:11 PM End time: 12/29/2011 5:46:13 PM Exit code: -1 Commandcall hadoop.cmd jar hadoop-examples-0.20.203.1-SNAPSHOT.jar wordcount /example/data/davinci.txt DaVinciAllTopWords Output (stdout)
Errors (stderr)org.apache.hadoop.mapred.FileAlreadyExistsException: Output directory DaVinciAllTopWords already exists at org.apache.hadoop.mapreduce.lib.output.FileOutputFormat.checkOutputSpecs(FileOutputFormat.java:134) at org.apache.hadoop.mapred.JobClient$2.run(JobClient.java:830) at org.apache.hadoop.mapred.JobClient$2.run(JobClient.java:791) at java.security.AccessController.doPrivileged(Native Method) at javax.security.auth.Subject.doAs(Subject.java:415) at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1059) at org.apache.hadoop.mapred.JobClient.submitJobInternal(JobClient.java:791) at org.apache.hadoop.mapreduce.Job.submit(Job.java:465) at org.apache.hadoop.mapreduce.Job.waitForCompletion(Job.java:494) at org.apache.hadoop.examples.WordCount.main(WordCount.java:67) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:601) at org.apache.hadoop.util.ProgramDriver$ProgramDescription.invoke(ProgramDriver.java:68) at org.apache.hadoop.util.ProgramDriver.driver(ProgramDriver.java:139) at org.apache.hadoop.examples.ExampleDriver.main(ExampleDriver.java:64) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:601) at org.apache.hadoop.util.RunJar.main(RunJar.java:156)
|
Keywords: Azure, Hadoop, Apache, BigData, Cloud, MapReduce