Apache Hadoop on Windows Azure Part 2 - Creating a Pi Estimator Hadoop Job
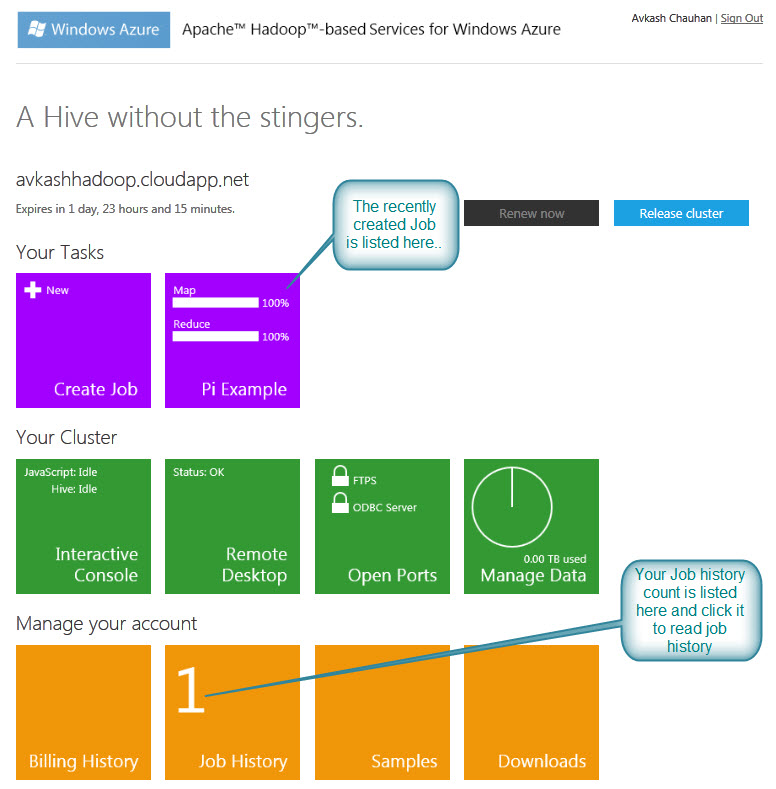
Once you have created a cluster in Windows Azure, you will have a few prebuilt samples provided in your account so let’s select “Samples” as below:
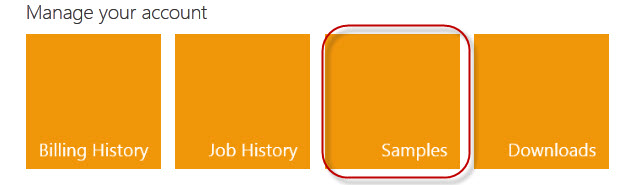
In the Hadoop Samples gallery lets select “Pi Estimator” sample below:
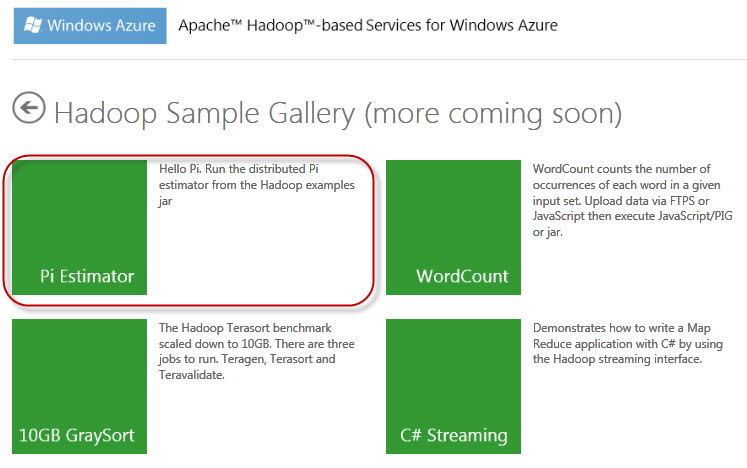
You will see “Pi Estimator” sample details as below. After reading the details and descriptions, you can go ahead and deploy the job to your cluster just in a single click as below:
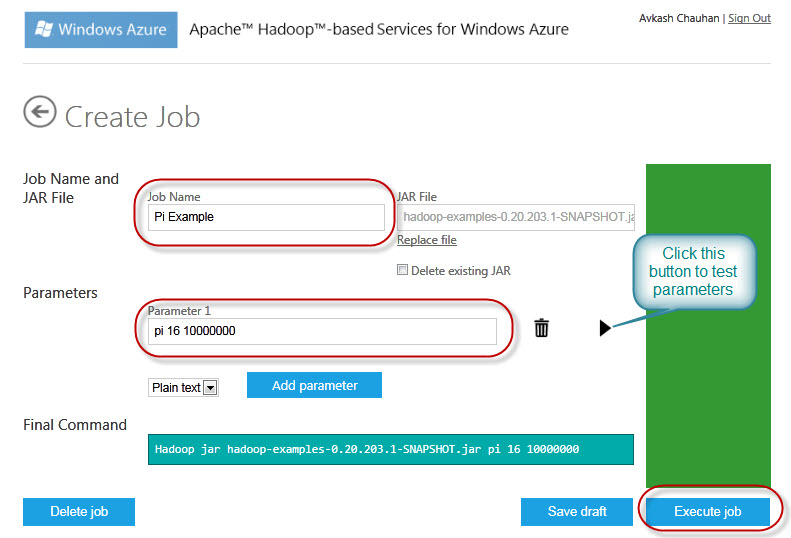
A new Job windows will open where you can add and verify parameters used with our Hadoop Job. Below you can verify the parameters and then when ready just “Execute Job”:
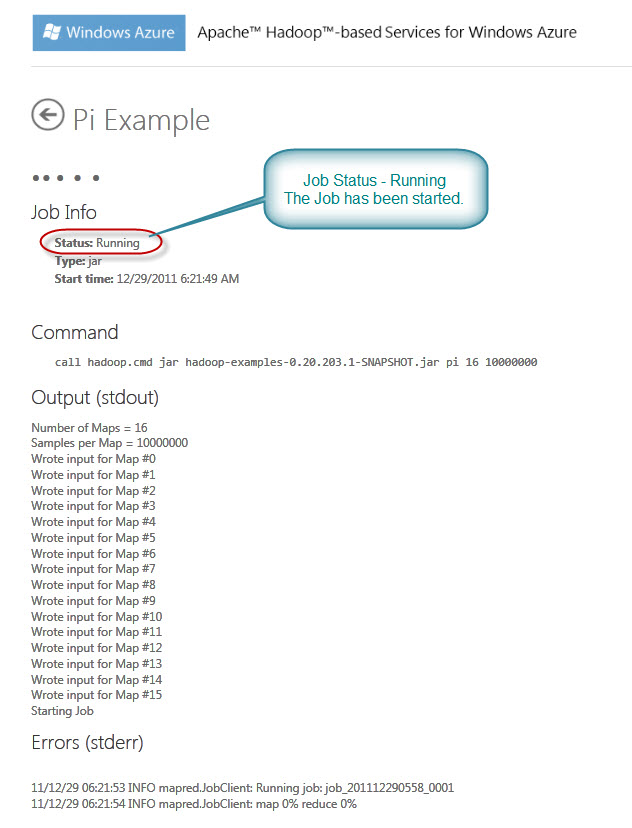
Now the Hadoop job will start and notification will be shown as below:
Finally when the Job will be completed you will see the final results as below:
Pi Example ••••• Job Info Status: Completed Sucessfully Type: jar Start time: 12/29/2011 6:21:49 AM End time: 12/29/2011 6:22:56 AM Exit code: 0 Command call hadoop.cmd jar hadoop-examples-0.20.203.1-SNAPSHOT.jar pi 16 10000000 Output (stdout) Number of Maps = 16 Samples per Map = 10000000 Wrote input for Map #0 Wrote input for Map #1 Wrote input for Map #2 Wrote input for Map #3 Wrote input for Map #4 Wrote input for Map #5 Wrote input for Map #6 Wrote input for Map #7 Wrote input for Map #8 Wrote input for Map #9 Wrote input for Map #10 Wrote input for Map #11 Wrote input for Map #12 Wrote input for Map #13 Wrote input for Map #14 Wrote input for Map #15 Starting Job Job Finished in 63.639 seconds Estimated value of Pi is 3.14159155000000000000 Errors (stderr) 11/12/29 06:21:53 INFO mapred.JobClient: Running job: job_201112290558_0001 11/12/29 06:21:54 INFO mapred.JobClient: map 0% reduce 0% 11/12/29 06:22:20 INFO mapred.JobClient: map 12% reduce 0% 11/12/29 06:22:23 INFO mapred.JobClient: map 50% reduce 0% 11/12/29 06:22:32 INFO mapred.JobClient: map 62% reduce 0% 11/12/29 06:22:35 INFO mapred.JobClient: map 100% reduce 0% 11/12/29 06:22:38 INFO mapred.JobClient: map 100% reduce 16% 11/12/29 06:22:44 INFO mapred.JobClient: map 100% reduce 100% 11/12/29 06:22:55 INFO mapred.JobClient: Job complete: job_201112290558_0001 11/12/29 06:22:55 INFO mapred.JobClient: Counters: 27 11/12/29 06:22:55 INFO mapred.JobClient: Job Counters 11/12/29 06:22:55 INFO mapred.JobClient: Launched reduce tasks=1 11/12/29 06:22:55 INFO mapred.JobClient: SLOTS_MILLIS_MAPS=189402 11/12/29 06:22:55 INFO mapred.JobClient: Total time spent by all reduces waiting after reserving slots (ms)=0 11/12/29 06:22:55 INFO mapred.JobClient: Total time spent by all maps waiting after reserving slots (ms)=0 11/12/29 06:22:55 INFO mapred.JobClient: Rack-local map tasks=1 11/12/29 06:22:55 INFO mapred.JobClient: Launched map tasks=16 11/12/29 06:22:55 INFO mapred.JobClient: Data-local map tasks=15 11/12/29 06:22:55 INFO mapred.JobClient: SLOTS_MILLIS_REDUCES=22906 11/12/29 06:22:55 INFO mapred.JobClient: File Input Format Counters 11/12/29 06:22:55 INFO mapred.JobClient: Bytes Read=1888 11/12/29 06:22:55 INFO mapred.JobClient: File Output Format Counters 11/12/29 06:22:55 INFO mapred.JobClient: Bytes Written=97 11/12/29 06:22:55 INFO mapred.JobClient: FileSystemCounters 11/12/29 06:22:55 INFO mapred.JobClient: FILE_BYTES_READ=2958 11/12/29 06:22:55 INFO mapred.JobClient: HDFS_BYTES_READ=3910 11/12/29 06:22:55 INFO mapred.JobClient: FILE_BYTES_WRITTEN=371261 11/12/29 06:22:55 INFO mapred.JobClient: HDFS_BYTES_WRITTEN=215 11/12/29 06:22:55 INFO mapred.JobClient: Map-Reduce Framework 11/12/29 06:22:55 INFO mapred.JobClient: Map output materialized bytes=448 11/12/29 06:22:55 INFO mapred.JobClient: Map input records=16 11/12/29 06:22:55 INFO mapred.JobClient: Reduce shuffle bytes=448 11/12/29 06:22:55 INFO mapred.JobClient: Spilled Records=64 11/12/29 06:22:55 INFO mapred.JobClient: Map output bytes=288 11/12/29 06:22:55 INFO mapred.JobClient: Map input bytes=384 11/12/29 06:22:55 INFO mapred.JobClient: Combine input records=0 11/12/29 06:22:55 INFO mapred.JobClient: SPLIT_RAW_BYTES=2022 11/12/29 06:22:55 INFO mapred.JobClient: Reduce input records=32 11/12/29 06:22:55 INFO mapred.JobClient: Reduce input groups=32 11/12/29 06:22:55 INFO mapred.JobClient: Combine output records=0 11/12/29 06:22:55 INFO mapred.JobClient: Reduce output records=0 11/12/29 06:22:55 INFO mapred.JobClient: Map output records=32 |
Finally you can use the Arrow button to go back and you will see your final Job count and history is listed as below: