Skalowalne środowisko do przechowywania obrazków
Przechowywanie plików w bezpieczny sposób we własnej serwerowni to nie lada wyzwanie dla każdej dużej firmy. Wymagane są ogromne inwestycje nie tylko w macierze dyskowe, ale również pozostałą część infrastruktury. Do tego przy projektowaniu takiego rozwiązania należy też wziąć pod uwagę bezpieczeństwo danych, czyli także kopie zapasowe. Jeśli serwis szybko rośnie i użytkownicy umieszczają coraz więcej plików planowanie takiej architektury może być trudne.
Z pomocą przychodzą rozwiązania w chmurze. Wyobraźcie sobie duży portal internetowy, który odwiedzany jest codziennie przez wiele milionów internautów. To może być serwis społecznościowy, strona z najnowszymi plotkami o gwiazdach, ale też duża platforma e-commerce z ogłoszeniami. Co jeśli takich plików użytkowników mamy kilka miliardów. Jeśli każdy obrazek w Internecie ma średnio 100kB otrzymujemy setki terabajtów danych nie tylko do przechowania, ale przede wszystkim udostępnienia w sieci. Jak wyskalować rozwiązanie które ma przechowywać np. 500TB plików, które będzie w stanie obsłużyć 5 miliardów zapytań miesięcznie?

Rozwiązań jest wiele – skupmy się jednak na najprostszym, ale najskuteczniejszym. Wykorzystać w tym celu możemy Blob Storage.
Blob Storage świetnie nadaje się do przechowywania:
- Dokumentów
- Danych społecznościowych takie jak zdjęcia, wideo, muzyka i blogi
- Kopii zapasowych plików, komputerów, baz danych i urządzeń
- Obrazów i tekstów dla aplikacji sieci Web
- Danych konfiguracji dla aplikacji w chmurze
- Danych big data takich jak dzienniki i inne duże zestawy danych
W zależności od tego jak często chcemy dostawać się do danych wybrać musimy jedną z opcji. Oczywiście mając do dyspozycji wersję „Hot” i „Cold” wybierzemy tą pierwszą, ponieważ do drugiej mamy chociażby wyższe ceny dostępu, bo jest stworzona z myślą o przechowywaniu kopii zapasowych, niż plików o bezpośrednim dostępie. Musisz pamiętać, że wysyłanie danych do chmury jest bezpłatne, płaci się tylko za pobieranie danych.
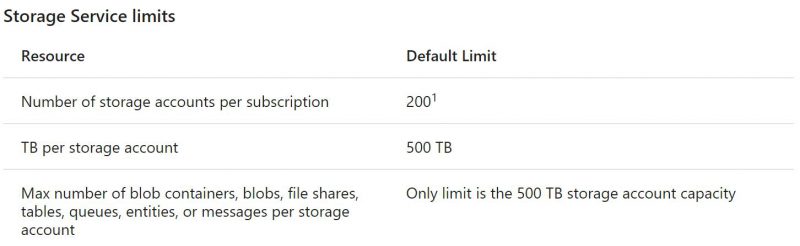
Ponieważ każdy z magazynów ma limit przechowywanych danych warto od razu założyć kilka kont i na nich pracować. Domyślnie każde konto ma limit 500TB danych. Nawet jeśli zakładamy, że mamy mniej danych do przechowania warto założyć kilka oddzielnych kont, żeby ruch rozłożyć pomiędzy oddzielnymi kontami. Nie ma co przejmować się limitem kont bo możemy mieć ich aż 200 na każdej subskrypcji
Konta mają ograniczenie też co do ilości zapytań. Na szczęście dla magazynów typu blob każde konto ma aż 20 tysięcy zapytań na sekundę co daje nam ponad 53,5 mld zapytań miesięcznie. Nasze założenia to ponad 5 mld odwołań czyli 1/10 możliwości konta. Jednak dla zapewnienia sobie odpowiedniej wydajności i pojemności najlepiej założyć i tak minimum 2 konta, a przy tej skali działalności sugerowałbym max 10. Każdy storage może mieć ustawioną politykę replikacji. Najniższą i najtańszą opcją jest LRS czyli „Local-reduntant storage” – tutaj nasze dane mają kilka kopii w ramach jednego data center. Opcją droższą, ale bezpieczniejszą jest GRS i RA-GRS. Oba robią kolejne kopie w zapasowym DC, a RA-GRS dodatkowo umożliwia nam wybranie z którego miejsca chcemy każdorazowo sięgać po plik. Dostęp do plików odbywa się na podstawie unikalnego linka (w przypadku bloba publicznego) lub klucza jeśli używamy blob storage w trybie „Private”. Do naszego celu odradzam kontener publiczny, bo każdy będzie mógł nie tylko anonimowo odczytać plik, ale też wylistować wszystkie nasze pliki w katalogach.
Jeśli planujemy więc udostępniać użytkownikowi bezpośredni dostęp do pliku jedyna opcja to „Public blob”. Publiczne adresy zawsze są w formacie https://<konto>.blob.core.windows.net/<kontener>/<plik> 
Chyba, że użyjemy opcji „Custom domain” możemy wtedy „ukryć” domyślny adres platformy Microsoft Azure za własną domeną.
Jeśli zaś pliki chcemy zakryć np. za proxy (o tym później) to idealny jest tryb „Private”. Możemy też użytkownikowi dać tymczasowy dostęp do prywatnego pliku korzystając z "Shared Access Signature" gdzie możemy określić też czas dostępu, po którym link wygaśnie.
Do kont możemy dostać się za pomocą API lub gotowych bibliotek dla większości popularnych języków programowania takich jak PHP, .NET, Node.js, Java, C++, Python, Ruby i inne.
Aby podejrzeć zawartość naszego katalogu w chmurze możemy użyć bezpłatnego oprogramowania dla Windows o nazwie „Microsoft Azure Storage Explorer”. Każde konto ma po dwa klucze dostępu „Access keys”. W przypadku, kiedy zmieniamy jeden z kluczy aplikacja powinna automatycznie łączyć się korzystając z drugiego. Dzięki temu, nasz serwis będzie zawsze udostępniał pliki nawet podczas rutynowej zmiany haseł dostępów. Dostęp do kluczy mamy z poziomu Portalu Azure lub skryptów PowerShell.
Wspomniałem wcześniej o tym, że moglibyśmy chcieć ukryć pliki za proxy. Możemy to zrobić z kilku powodów. Jednym z nich mogą być koszty transmisji danych, innym własna sieć CDN. Jeśli mamy własne DC, w którym chcemy hostować proxy możemy między serwerownią, a Azure uruchomić łącze MPLS czyli ExpressRoute. Dzięki temu będziemy mieć gwarantowaną przepustowość, ale też możemy nie płacić za przesłane dane.
Pewnie zastanawiasz się w jaki sposób przesłać wiele terabajtów danych do Azure? Nic trudnego. wystarczy skorzystać z usługi Azure Import/Export czyli wysłać do serwerowni Microsoftu dyski twarde z danymi. Więcej o usłudze dowiesz się pod dedykowaną stroną. W ten sposób można szybciej i wygodniej przesłać duże ilości danych nie obciązając łącz in ternetowych.
Rozwiązań hostowania plików dla dużego serwisu internetowego jest wiele. Blob Storage wydaje się najprostszy, najtańszy i najbardziej uniwersalny, dlatego postanowiłem go opisać. Chętnie w komentarzach przeczytamy jakie wy macie wyzwania z przechowywaniem plików w swojej firmie i chętnie doradzimy jak sobie z nim poradzić korzystając z Microsoft Azure.