Raporty i analityka sprzedaży w hurtowni danych Azure
Prowadząc analitykę sprzedaży, często zachodzi potrzeba porównania specyficznych metryk rok do roku. Jeżeli dodatkowo ilość transakcji jest z miesiąca na miesiąc coraz większa, klasyczne środowisko analityczne które projektowaliśmy i wdrożyliśmy kilka lat temu zaczyna nam niedomagać. Potężne serwery z ogromną ilością pamięci RAM oraz wydajne przestrzenie dyskowe wydają się być dosyć stare. Koszty utrzymania także nie są niskie. Przeliczanie kostek OLAP o setkach miar odbywa się w weekend i musi być gotowe na poniedziałek rano, aby można było rozpocząć pracę. Trwa to jednak coraz dłużej. Dodatkowo proces raportowania zaczyna przeciążać serwery w ciągu normalnego tygodnia pracy. Stajemy przed dylematem: spróbować optymalizacji schematów i modeli danych, co pozwoli przetrwać jeszcze 3-4 miesiące, zainwestować w kolejny sprzęt który będzie w pełni wykorzystywany tylko w weekend, czy może spróbować zmienić podejście i wykorzystać chmurę Azure.
Wspólnie z kilkoma klientami podjęliśmy dyskusję, która ostatecznie obróciła się w warsztaty Proof of Concept. Wśród kilku możliwych scenariuszy wybraliśmy dwa, które cechują się różnym stopniem skomplikowania, wpływającym także na szybkość wdrożenia:
Scenariusz 1 - Dobudowanie kolejnego serwera OLAP w Azure jako maszyny wirtualnej i rozkładanie obciążenia dla raportowania w ciągu tygodnia pracy
Zalety:
- Szybkie wdrożenie – zestawienie VPN, utworzenie instancji OLAP, ładowanie danych – kilka dni
- Prawdopodobnie szybsze przeliczanie kostek OLAP
- Możliwość dynamicznego reagowania na zwiększone zapotrzebowanie na moc i pojemność – skalowanie instancji i dokładanie kolejnych dysków
Wady:
- Istniejące problemy ze strukturami i modelami danych pozostają, przez co środowisko nadal będzie się rozrastało a przetwarzanie trwało coraz dłużej
- Potrzeba wdrożenia mechanizmu rozkładania ruchu dla użytkowników raportowania
Scenariusz 2 - Budowa rozwiązania w oparciu o skalowalne usługi Azure SQL Data Warehouse i Azure Analysis Services oraz wykorzystanie raportowania w PowerBI
Zalety:
- Migracja do architektury MPP (trochę więcej o samej usłudze klasy MPP można przeczytać tutaj) dla hurtowni danych oraz modelu tabular dla usługi analitycznzych
- Dynamika skalowania wydajności na poziomie przesuwania suwakiem DWU oraz QPU
- Eliminacja drogich w utrzymaniu serwerów i macierzy w lokalnych centrach przetwarzania danych
- Duża elastyczność budowania raportów w PowerBI
- Raporty PowerBI dostępne przez Internet, także na urządzenia mobilne
Wady:
- Konieczność zaplanowania odpowiednich mechanizmów dystrybucji danych dla architektury MPP
- Wymaga zaangażowania klienta oraz partnera, który przygotuje nowy lub dostosuje obecny model danych, przeprowadzi testy i przeniesie raportowanie do PowerBI – kilka do kilkunastu tygodni
Sprawdzamy scenariusz 1
Składniki:
- Azure VPN Gateway - Route Based High-Performance
- Azure Virtual Machine - GS2 -> GS5, MSSQL 2016 Enterprise
- Azure Storage - 8x P30
- Azure Automation - Start/Stop/Skalowanie
- Azure Log Analytics - na potrzeby analizy logów, głównie MSSQL
- Azure Virtual Network - oczywiście :)
Użytkownicy korzystający z kostek OLAP autoryzują się przy pomocy klasycznej domeny Active Directory, zatem należy zapewnić możliwość połączenia z sieci lokalnej do Azure, ale i w przeciwną stronę - na potrzeby dostępu do Active Directory. Do testów posiadaliśmy dosyć szybkie łącze do Internetu, zestawiony został Azure VPN Gateway w trybie Route-Based i rozmiarze High-Performance, co dało wydajność na poziomie 200Mb/s. W zupełności wystarczyło to do załadowania danych do kostek OLAP w Azure i nie powodowało znaczących opóźnień przy pobieraniu wyników przez użytkowników końcowych.
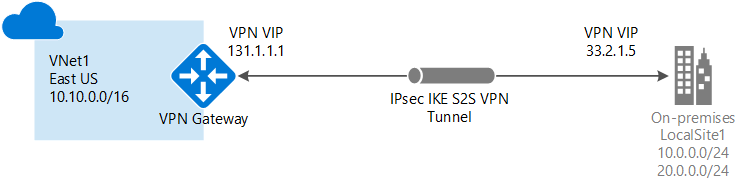
Utworzona została maszyna GS2 z MSSQL Server 2016 Enterprise. Aby zapewnić wydajność dla danych, dołączone zostało 8 dysków P30 (SSD) w stripingu. GS2 jest najmniejszym rozmiarem maszyny serii G do którego możemy dopiąć 8 dysków dla danych, a w przyszłości skalować w górę do GS5. Dołączona została do Azure Log Analytics na potrzeby zbierania i analizy logów.
Ciekawostka zaobserwowana w trakcie testów, to że na potrzeby rozwiązania zastosowana została maszyna GS5, która de facto nie była odpowiednikiem obecnie stosowanych serwerów we własnej infrastrukturze. Konfiguracja GS5 to kilka razy mniej pamięci RAM oraz znacznie mniejsza moc obliczeniowa, która w efekcie pozwoliła osiągnąć zbliżony do obecnie uzyskiwanego czas procesowania kostek. Istotny jest również fakt, że użytkownicy łączący się do kostek OLAP za pośrednictwem Excel'a dostępnego na własnych stacjach roboczych uzyskiwali wydajność zbliżoną, a niejednokrotnie większą niż w przypadku obecnie stosowanych serwerów. Wniosek z obserwacji jest bardzo prosty. Uwzględniając niewielki nakład pracy udało się zapewnić porównywalny wydajnościowo dostęp do zasobów OLAP. Z perspektywy skalowalności rozwiązań tej klasy jest to bardzo istotny argument, pozwalający na wykorzystanie platformy Azure jako naturalnego rozszerzenia własnej infrastruktury przy zachowaniu pełnej kompatybilności rozwiązania z obecnie stosowanymi narzędziami.
Po przetestowaniu wydajności serwera w Azure, po stronie klienta skonfigurowany został prosty load balancer oparty o HAProxy, dzięki czemu użytkownicy byli równomiernie rozkładani pomiędzy serwerem lokalnym a serwerem w Azure. Zapewniło to przezroczystość użytkowania takiego rozwiązania ale i dodatkową elastyczność. W razie gdyby zaszła potrzeba wyłączenia któregoś z serwerów, użytkownicy będą kierowani na drugi. Łatwo także dodać do takiego scenariusza kolejne serwery.
Całość rozwiązania była szczególnie zadowalająca ze względu na prostotę i szybkość wdrożenia. Pozwoliła na odciążenie serwerów lokalnych w przeciągu kilku dni. Niestety, podobnie jak środowiska w lokalnych centrach danych, przez wykorzystanie instancji maszyn wirtualnych - jest to najmniej elastyczne i optymalne kosztowo rozwiązanie. Można oczywiście używając Azure Automation startować/zatrzymywać serwery czy zmieniać ich rozmiar, ale jest to w pewnym stopniu mniej automatyczne niż pozostałe scenariusze.
Sprawdzamy scenariusz 2
Składniki:
- Azure SQL Data Warehouse - 100->1000 DWU
- Azure SQL Database
- Azure Data Factory - wraz z Data Management Gateway
- Azure Storage
- PowerBI - interaktywne raportowanie i wizualizacja danych
Scenaiursz numer 2 to o podejście o jeden, a nawet kilka kroków dalej, niż scenariusz 1. Pierwszy krok to zmiana lokalizacji hurtowni danych stanowiącej źródło danych dla kostek analitycznych. W scenariuszu nr 1 hurtownia danych pozostawała cały czas na lokalnych serwerach firmy. Tymczasem w tym podejściu zdecydowaliśmy się na jej przeniesienie na platformę Azure, co więcej ze względu na wolumin danych (5 TB) oraz wymagania w zakresie wydajności rozwiązania zdecydowaliśmy się na wykorzystanie SQL Data Warehouse. W tym miejscu pojawiła się konieczność pierwszej ze zmian - sposób zasilania hurtowni. DWH wymaga zasilenia danymi z baz źródłowych. Wykorzystaliśmy do tego Azure Data Factory który w dosyć przyjemny sposób pozwala na kopiowanie danych pomiędzy różnymi bazami danych, a w naszym wypadku, do DWH. Wykorzystując Data Management Gateway, będący częścią Azure Data Factory, nie musieliśmy zestawiać dedykowanej komunikacji VPN, ponieważ Data Management Gateway zapewnił zabezpieczenie transmisji danych.
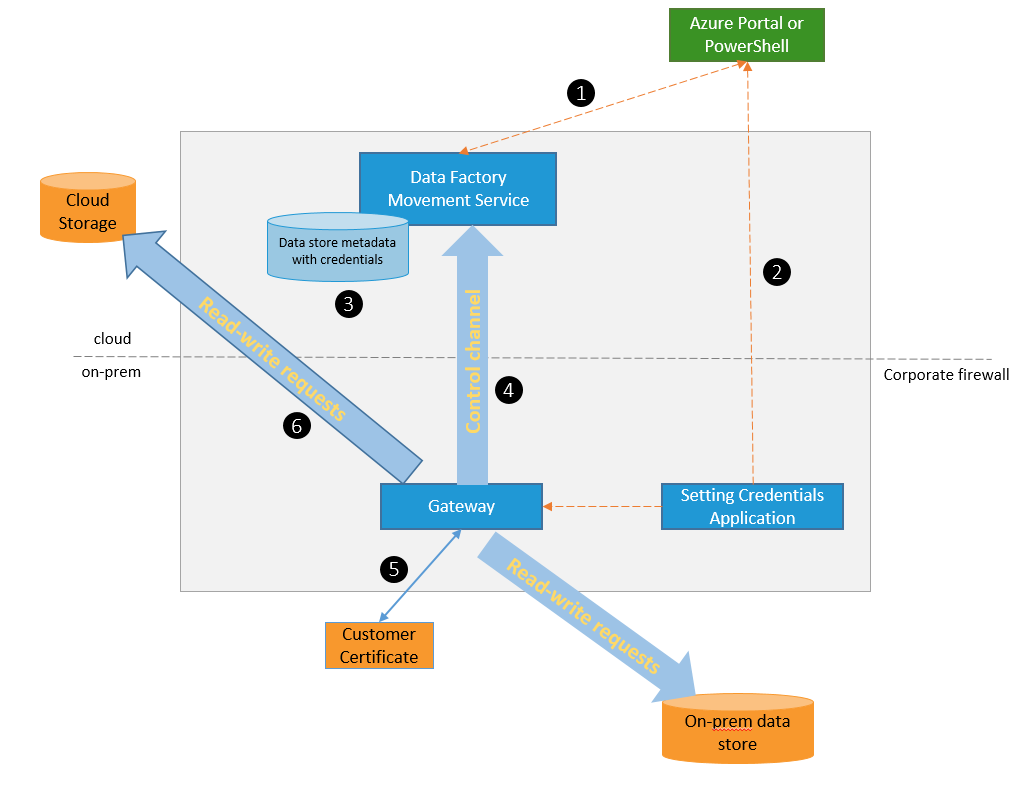
Warto w tym miejscu podkreślić, że w pełną efektywność architektury MPP, w jakiej działa SQL Data Warehouse, uzyskujemy poprzez zrównoleglenie operacji na niezależnych węzłach obliczeniowych(compute nodes), w tym również ładowania danych. Właśnie dlatego ładowanie odbywało się z wykorzystaniem funkcjonalności Polybase, która korzystaja z bezpośredniego dostępu do zasobów obliczeniowych usługi (compute node). Korzystając z tego podejścia udaje się osiągnąć imponujące wyniki. Co więcej już w tym miejscu jesteśmy w stanie wykorzystać benefit łatwości skalowania usługi i na czas ładowania danych "podkęcić" hurtownię wydajność hurtowni. W naszym przypadku nie było to nawet konieczne, a przeładowanie dziennej partii danych (ok 6 GB), zajęło nieco ponad 60 minut ( uwzględniając transfer danych z serwerów wewnątrz obecnej infrastruktury i ograniczenia łącza internetowe). W przypadku architektury MPP kluczem do sukcesu jest stosowana dystrybucja danych. Dystrybucja w przypadku SQL Data Warehouse zawsze odbywa się pomiędzy 60 baz danych, które obsługiwane są w obrębie dostępnych węzłów obliczeniowych usługi. Skalowanie usługi (zmiana ilości DWU), to zmiana ilości węzłów obliczeniowych, ale również reorganizacja dystrybucji pomiędzy dodawane/odejmowane węzły.
Mając dane odpowiednio załadowane do hurtowni przystąpiliśmy do kolejnego kroku - udostępnienie danych ma potrzeby analizy i raportowania użytkownikom końcowym. Mając do dyspozycji wydajny silnik bazy danych większość zapytań agregujących dane może być realizowana bezpośrednio na hurtowni danych. Jednak jakoś mimo wszystko nadal nie wyobrażamy sobie użytkowników końcowych, zwłaszcza biznesowych posługujących się z zapytaniami TSQL. Właśnie dlatego zdecydowaliśmy się użyć narzędzia jakim jest Power BI. Dzięki możliwości wykorzystania Power BI jako interfejsu dla użytkowników końcowych, wyeliminowaliśmy konieczność posługiwania się zapytaniami TSQL, które zastąpione zostały mechanizmem "Przeciągnij & upuść". Power BI to również doskonałe narzędzie do modelowania danych. Dzięki możliwości wykorzystania języka wyrażeń DAX (Data Analysis Expressions) udało się zbudować dodatkowe miary wyliczalne np. wartości średnie, dynamika sprzedaży czy klasyka analizy, czyli miary typu Month to Date(MTD), Year over Year (YOY), które zapewniają pełną swobodę dostępu dla użytkowników końcowych. Pomimo, że większość operacji wykonywana była czasy odpowiedzi zapytań liczone były w dziesiątkach sekundach. Jednak apetyt rośnie w miarę jedzenia, właśnie dlatego, aby zapewnić jeszcze większą wydajność zdecydowaliśmy się na dodanie dodatkowe komponentu - usługi analitycznej Azure Analysis Services, która jest odzwierciedleniem dobrze znanej z SQL Server usługi Analysis Services w modelu Tabular. Efekt? Dane z hurtowni ładowane są do struktur tabelarycznych Azure Analysis Services, na poziomie AAS uzyskujemy możliwości swobodnego modelowania korzystając również z wyrażeń DAX, a Power BI łączy się do wydajnego silnika, który na zapytania na zbiorze kilkuset milionów rekordów odpowiada w pojedynczych sekundach.
Power BI oprócz samej swobody dostępu do danych gwarantuje dostępność do danych na dowolnym urządzeniu mobilnym, jako, że mobilna aplikacja Power BI dostępna jest na każdym systemie operacyjnym od iOS, przez Android po Windows Phone.
W przypadku bardzo dużych zbiorów danych oraz wydajnej hurtowni (jak w przypadku Azure SQL Datewarehouse), można skorzystać również z opcji Azure Analysis Services w trybie DirectQuery. W jakim celu? Cel jest prosty wydobywać wszystko co najlepsze z Analysis Services czyli swoboda dostępu do użytkownika, mechanizmy bezpieczeństwa na poziomie wierszy z wykorzystaniem DAX, cachowanie i optymalizacja zapytań przez silnik Analysis Services (szczególnie widoczne w najnowszej wersji Analysis Srvices) oraz co w wielu przypadkach najważniejsze - wyeliminowanie konieczności procesowania struktur i danych Analaysis Services.
Efekt końcowy rozwiązania najelpiej obrazu poniższy schemat
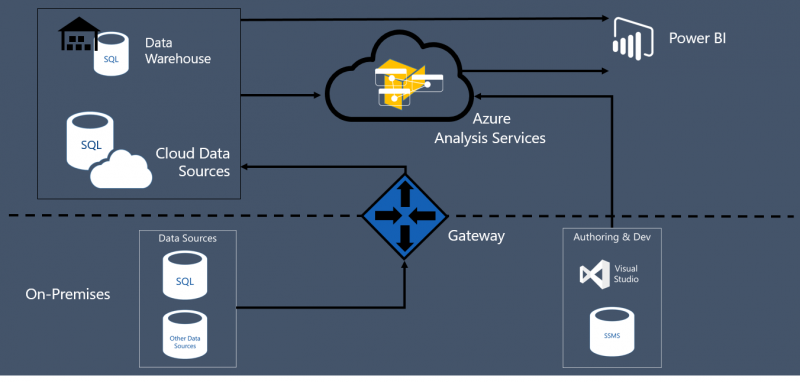
Reasumując rosnące zapotrzebowanie w zakresie analizy danych to wyzwanie, wyzwanie, które w zależności od potrzeb i czasu jakim dysponujemy, można zaadresować w ciągu kilku dni, podobnie jak przedstawiliśmy to w Scenariuszu nr 1 lub wykorzystać elastyczność i skalowalność usług analitycznych i hurtowni danych dostępnych na platformie Azure
Autorzy:
- Bartłomiej Graczyk
- Maciej Stopa