Loading performance – DWLoader, distribution keys and source files
There are several ways to load data in PDW: SSIS, DWLoader client, and with the latest release BCP also(*)
In this post I will discuss a specific performance scenario when loading data with DWLoader.
You can refer to .CHM for all details on DWLoader client, parameters, syntax, remarks…
The first thing to check when looking into DWLoader performance issues is always database and table design. Bad distribution key might have an impact on the loading process. If we choose a distribution key that causes high data skew, the distribution receiving the higher amount of data might slow the entire process.
There is another twist to the matter though. Even with a good distribution key we might encounter a performance problem when loading data.
What's wrong then?
The answer lies most likely in the source file being used.
On a test scenario, a 70GB flat file (200+ mln rows) is being used, with a specific distribution key, that maps to 400 different values. Quite small sample of the entire record set, but if looked at after the load, the key itself is not a bad distribution key as it shows in the end a small difference in the number of rows belonging to every distribution.
Still the load took seven hours, while we could expect it to be in the range of minutes to complete.
The problem here lies in the fact that the file is sorted on the distribution key we have chosen (CARD_ID int), causing the values belonging to the same distribution to be grouped together.
With 400 distinct values over 200+ mln rows we have approximately distributions of 500000 rows (200mln / 400).
The way the load process works, makes this an extremely inefficient scenario.
DWLoader will read the load file in chunks, and send them in round robin fashion to the compute nodes. Every compute node (the DMS service on the node) will then hash the data and evaluate the distribution it needs to be sent.
In our case the amount of rows that belong to a single distribution (500.000) is too high to be sent as a single chunk to the Data Movement Service (DMS) of a single compute node, so multiple DMS's (from the different nodes) will work on the same value of the distribution key and every CMP node will end up working on a chunk of data that belongs to the same exact distribution.
Every DMS will be sending the data it is working on to the same final location. This will resemble more to a serial process than to a parallel load.
The picture below shows a possible outcome:
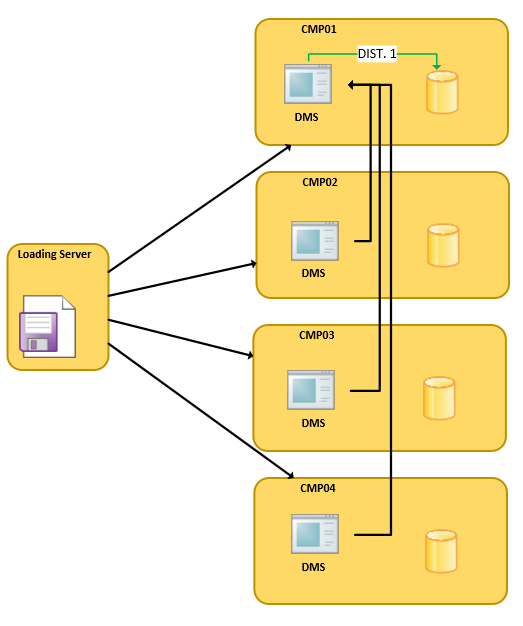
- DWLoader reads chunks of the files and sends them in a round robin fashion to the DMS on all compute nodes.
- DMS on every compute node hashes the distribution key of every row if the chunk it is working on and determines it belongs to (for example) DIST 1 on CMP01. Thus sends the data to the DMS on CMP01 to be written to the proper distribution.
In this scenario, until work for all 500000 rows for the value of the distribution key is complete, only CMP01 will be writing data. Until that is complete the other Compute Nodes will NOT be writing anything, but will only be sending data to CMP01. All other distributions will be written in the same way, ending up with a “serial” processing as we will process only 1 distribution at a time.
We have then removed the sorting, generating the source file in a different way which caused the distribution key values to be scattered within the file. The final result we have worked on still contained rows grouped together on the value of the distribution key, but in smaller groups. In this second scenario the chunks being sent to every DMS contains more than one group of values, allowing a real parallel load to occur:
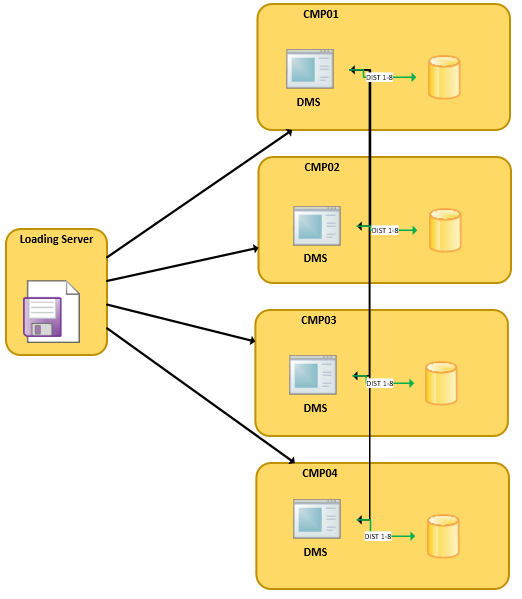
All DMS are sending AND receiving rows to write to the destination.
Load times went from 7 hours to below 20 minutes.
Troubleshooting performance above, I have added a further step to the process. Reviewing database design, I have identified another field I could use as a distribution key (TICKET_ID int). Looking at the workload I needed to perform, even the new field would fit my needs, so I have changed the table design to be distributed on the new field.
The new key has a higher number of distinct values (2mln), causing each distribution to have around 100 values in it (200 mln / 2 mln). The original file is by accident sorted on this key as well, causing all the values for the new one also to be grouped together. With the new key though, the chunks being sent to every DMS contain more than one value of the distribution key, again allowing a real parallel load to occur.
The new distribution key proved to be far more efficient than the original one. The same original file sorted on CARD_ID, which ended up loading in 7 hours, completed in roughly 10 minutes when using the new key (TICKET_ID) with no need to sort the file in a different way.
The example above gives us two major takeaways:
- A good distribution key might not be sufficient to address all load performance issue. The source file is also playing a huge part in the process.
- A highly selective distribution key can greatly improve data movements performance. If possible (given the workload and design constraints) it would always be better to use a more selective field as a distribution key.
As a final note, an excerpt from DBCC PDW_SHOWSPACEUSED:
| CARD_ID | TICKET_ID |
| Rows | Rows |
| 11355800 | 11534336 |
| 11661639 | 11705516 |
| 8097049 | 11534336 |
| 11775011 | 11534336 |
| 12957618 | 11664044 |
| 14184063 | 11534336 |
| 9981716 | 11645572 |
| 12027197 | 11682265 |
| 14023967 | 11534336 |
| 11146783 | 11494604 |
| 9533799 | 11522956 |
| 12185911 | 11502103 |
| 11651097 | 11474002 |
| 14737011 | 11534336 |
| 11777282 | 11534336 |
| 8391977 | 11534336 |
CARD_ID wasn't a bad distribution key, but TICKET_ID was better.
(*) BCP functionality was introduced with AU4 hotfix 3100765 (build number 10.0.7568.0)