Azure Functions, Compute, Containers, How to
Learn how to orchestrate serverless functions by scraping APIs in 8 minutes
Posted on
8 min read
This blog post was authored by Maxime Rouille, Cloud Developer Advocate II, Microsoft.
Our scenario
The project I’m working on requires me to retrieve information from multiple sources like the NuGet and GitHub API. Let’s bring into focus how I’m downloading data from the GitHub API. If you follow me on Twitter, you’ve probably already heard me talk about it.
Ever ended up on a sample that should be covering the problem you’re having, but it just doesn’t work? Then, you check the last commit date only to realize that it’s been 2 years since the last commit. The way the cloud is evolving, that sample is almost no good to you.
Well, some of the repositories on the Azure-Samples organization have those exact issues, and it’s one of the many problems that I’m trying to solve.
There are tons of samples on the Azure-Samples organization on GitHub, and I want to be able to check them out to see which ones are “too old.” What does a user consider a valid sample? For me, a valid sample is an up to date sample.
We need a way to retrieve those over 900 samples and validate their last commit date.
However, we first need to be able to retrieve all that information.
File -> New Project -> Console Application
Our first instinct as programmers is to try to do it once through a console application. It’s the minimum amount of complexity. If you can’t make it work in a console, there’s no hope of making it work anywhere else.
So, I went ahead and started by consulting the GitHub API documentation, created a GitHub token and started hunting for the information I need.
I ended up using the Octokit library to do all of my API access. The code to retrieve the last commit date is below.
var github = new GitHubClient(new ProductHeaderValue("AzureSampleChecker")) { Credentials = new Credentials("") };
var lastCommit = await github.Repository.Commit.GetAll(repositoryId, new ApiOptions { PageSize = 1, PageCount = 1 });
var commit = lastCommit.FirstOrDefault()?.Commit;
var lastCommitDate = commit.Committer.Date;
//snipped: saving to the database
First problem: Running locally
Everything was running fine, but the problem for me at that point was it was just a single console application running locally. I could have just taken the application as-is to containers, but I saw another way to solve this. I saw another way to scale it up. Azure Functions would help me scale it up.
By migrating the existing code into an Azure Function, the problem now was that it was still just a console application running inside an Azure Functions. This will just not cut it. We’re just running the same workflow in sequence. We need to execute this workflow in parallel and be able to scale out.
Once you know all the repositories that you want to query, it becomes a distributed problem. How many repositories can I hit at once without having any state to correlate between them? The answer is all of them.
I needed to refactor to make this process more sturdy. I needed it to be durable.
Introducing Durable Functions
If you are new to serverless, there’s an excellent book by Jeremy Likness that can bring you up to speed. Azure Functions is Microsoft’s implementation of the serverless architecture. If you need a refresher, you can review the Azure Functions Overview on what is possible.
What is a Durable Function? With durable, it’s all about orchestration. Just like in music, the orchestrator ensures that everyone is following the melody, but it’s the responsibility of each musician to play their instrument.
Regarding Durable Functions, an orchestrator is in charge of starting and tracking a series of functions, but it’s the responsibility of each activities to execute their part. Think of the orchestrator as a workflow written in code and activities as the steps of the workflow. An orchestrator and an activity are still Azure Functions.
Let’s introduce two patterns that I’m using in my code.
Function Chaining
A pattern I want to cover quickly is function chaining. It’s the most straightforward and most commonly used pattern.

Function Chaining
Everytime that your orchestrator awaits a function before running another one, you’re doing function chaining. Here’s the above image visualized in a code example.
[FunctionName("FunctionChaining")]
public static async Task RunFunctionChaining([OrchestrationTrigger]) DurableOrchestrationContext context)
{
await context.CallActivityAsync("F1", null);
await context.CallActivityAsync("F2", null);
await context.CallActivityAsync("F3", null);
await context.CallActivityAsync("F4", null);
}
Fan-Out/Fan-In
One of the Durable Functions design patterns I used is Fan-Out/Fan-In.
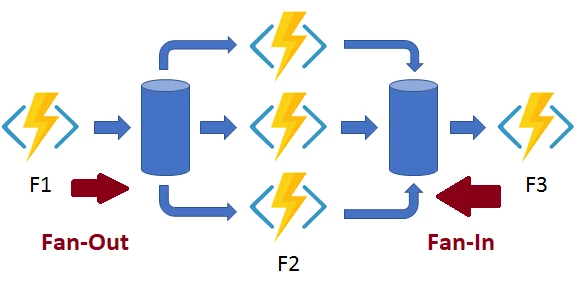
Fan-Out/Fan-In Pattern
Fanning out means that your orchestrator function (F1) starts as many functions (F2) as necessary in parallel with some initial parameters like the repository I want. Once all those functions have finished executing, we need a way to return the requested data to our orchestrator (F3). Keep in mind that, all those functions may not be executing on the same server. It is not as simple as a multi-threaded application. It’s a multi-threaded, multi-server, highly parallel execution workflow.
How would you do that in a local data center? A console application would retrieve the list of items on which you want to fan-out. Then, it would queue that list into a messaging system. Once queued up, you would have to have dequeue those messages asynchronously by other console applications that are on different servers. Each console applications would then be responsible for storing the result of their execution on shared storage. Once completed, you’d have to find a way to get the first console application to finish the workflow. Finishing the workflow would involve fanning in all the results back, and saving it to a database.
With Azure Functions, it’s as easy as returning an object. All the necessary work of storing the results of individual functions and aggregating them together is done automatically for you.
This scenario is a hard problem. Durable Functions just saved me easily one week of work and more days of testing, debugging, and refining the process.
Now that the introduction is complete let’s jump back to our scenario.
Orchestrators are special functions
Functions with the OrchestrationTrigger behaves widely differently than normal Azure Function. This trigger is what makes a normal Azure Function an Orchestrator Function. Just
Its behaviors are incredibly different than other Functions. It is called multiple times at different moment to orchestrate the execution of those functions. It is of the utmost importance that you do not calculate time and access external resources (e.g., SQL, Storage, API) in that context. The orchestrator is tasked to execute and track the status of those functions we started by executing itself repeatedly when something changes. You want the orchestrator function to be deterministic, meaning the same code executed at a different time need to give the same result. So no DateTime, no Math.Random or Guid.NewGuid() should be in an orchestrator.
It’s also important to note that every call that you make using CallActivityAsync won’t be executed more than once for the same orchestrator instance. Results are cached and handled by the Durable Functions.
CallActivityAsync is part of the concept that we call checkpoint and replay. In simpler terms, this allows resuming the execution of the orchestrator while remembering the state of the execution of previous activities we ran in a reliable way across servers.
Web Scraping scenario
Here’s the code for my sample orchestrator.
[FunctionName("DownloadSamples_Orchestrator")]
public static async Task RunOrchestrator([OrchestrationTrigger] DurableOrchestrationContext context, TraceWriter log)
{
var repositories = await context.CallActivityAsync("DownloadSamples_GetAllPublicRepositories", null);
var tasks = new Task[repositories.Count];
for (int i = 0; i < repositories.Count; i++)
{
tasks[i] = context.CallActivityAsync("DownloadSamples_UpdateRepositoryData", repositories[i]);
}
await Task.WhenAll(tasks);
var samplesToAdd = tasks.Select(x => x.Result).ToList();
await context.CallActivityAsync("DownloadSamples_SaveAllToDatabase", samplesToAdd);
}
So let’s decompose this together. First, I call a function to retrieve the list of over 900 Public Repositories available on Azure-Samples and await for the results before going any further. Then, we create an array of Tasks and go through our samples and start a function without an await for each of them. We’re fanning out the execution of those functions to be run and scaled by the cloud automatically. We’re not using await here. Otherwise, they would run sequentially instead of in parallel.
Then task then need to be awaited till completion. Finally, we aggregate the Samples object that has been returned by those functions into a list. Finally, we send it to a function to save them in a database. We’ve successfully fanned-in the results of 100s of functions. There is no need for a third-party system. No other configurations. No complex messaging architecture. Just code.
Just like that, we’ve made a complex parallel problem easy.
Advanced Scenario: Orchestrating Orchestrators with Sub Orchestrators
Isn’t it amazing? Now, I have an Orchestrator that instantiates over 900 DownloadSamples_UpdateRepositoryData functions to download data from the GitHub API. What would happen if I have multiple orchestrators of data ingestion that I want to make?
How do I orchestrate the orchestrators? We need another orchestrator of course! Here’s a simplified version of my code.
[FunctionName("MainDownloadOrchestrator_TimerStart")]
public static async Task TimerStart([TimerTrigger("0 0 7 * * *")]TimerInfo myTimer,
[OrchestrationClient]DurableOrchestrationClient starter,
TraceWriter log)
{
string instanceId = await starter.StartNewAsync("MainDownloadOrchestrator", null);
log.Info($"Started orchestration with ID = '{instanceId}'.");
}
[FunctionName("MainDownloadOrchestrator")]
public static async Task RunOrchestrator(
[OrchestrationTrigger] DurableOrchestrationContext context)
{
var runId = await context.CallActivityAsync("CommonActivityFunctions_CreateRun", null);
var downloadPipelines = new List();
downloadPipelines.Add(context.CallSubOrchestratorAsync("DownloadSamples_Orchestrator", runId));
downloadPipelines.Add(context.CallSubOrchestratorAsync("DownloadSomethingElse_Orchestration", runId));
//todo: add more orchestrators
await Task.WhenAll(downloadPipelines);
return context.InstanceId;
}
What does it do?
Create a single run that is going to be used to invoke every other data ingestion orchestrator.
All those orchestrators are all going to start at 7 am every day at the same time. They are all going to run as described before. Only this time, they also report back to another orchestrator.
Once you start implementing simple workflows, it becomes effortless to build complex scenarios out of simple ones. The same patterns we approached that were used to build a single orchestrator can be used to orchestrate multiple sub-orchestrators.
Why do I want this?
Imagine working on a team with many different processes that need to run in parallel. Maybe one team is working on the shipping process, the other on the payment process. With a single orchestrator to manage multiple sub orchestrators, it makes team collaboration easier.
In my case, what if someone else wants to add the parsing of another API? They can work on their orchestrator and plug it in my MainDownloadOrchestrator function, and that’s it.
Scraping data from an API is just a single scenario. Whether you are building an order processing system, a conference organization tool or the next revolution in IoT data processing, we know that you need a way to organize complexity within your solution. We know that you want to reuse more significant part of your system than a single function.
Durable Functions is how you build complex systems with serverless.
What is missing
What you haven’t seen implemented is how to handle rate limiting. GitHub API has a limit of 5000 (at the time of writing) API calls per hour which is more than enough for the use that I make of it.
However, if other teams were to query GitHub some more, I’d need to look into implementing it. I still don’t have an elegant solution for this, but it’s going to be something I’m looking to implement next.
Try it out
If you want to try it out, Azure Functions comes with a free quota even with a trial account. If you need an account, you can create one for free.
Contribute
Azure Functions is also open source. Look at these repositories if you want to contribute or just want to know what’s going on with the project.
Resources to get you started