Understanding serverless cold start
Posted on
6 min read
Update June 2019: Cold start mitigations for dynamic scaling functions are now available in the Premium plan. Read more here.
Cold start is a large discussion point for serverless architectures and is a point of ambiguity for many users of Azure Functions. The goal of this post is to help you understand what cold start is, why it happens, and how you can architect your solutions around it. To provide this explanation, we’ll be going deep into some technical details of how Azure Functions works behind the scenes.
Consumption plan vs. dedicated plan
Azure Functions comes in two main flavors, consumption and dedicated. The difference between the two is important, choosing one over the other not only dictates the behavior of your application but also how you’re billed. The consumption plan is our “serverless” model, your code reacts to events, effectively scales out to meet whatever load you’re seeing, scales down when code isn’t running, and you’re billed only for what you use. Plus, all of this happens without you thinking about what Microsoft Azure is doing behind the scenes. The dedicated plan on the other hand, involves renting control of a virtual machine. This control means you can do whatever you like on that machine. It’s always available and might make more sense financially if you have a function which needs to run 24/7. If you’re curious and want a more detailed explanation, check out our documentation.
What is cold start?
Broadly speaking, cold start is a term used to describe the phenomenon that applications which haven’t been used take longer to start up. In the context of Azure Functions, latency is the total time a user must wait for their function. From when an event happens to start up a function until that function completes responding to the event. So more precisely, a cold start is an increase in latency for Functions which haven’t been called recently. When using Azure Functions in the dedicated plan, the Functions host is always running, which means that cold start isn’t really an issue. So, our scope is narrowed to Functions running the serverless consumption model. Let’s go deeper.
What happens when I write a function?
Suppose you’re writing your first function. You’ve provisioned a function app, created your function based on one of our templates, and are modifying it to fit your business needs. You save, and now wait for your specified trigger to initiate your function. Later, your function triggers. When this process begins, since you haven’t yet executed anything, all your code and config exist only as files in Azure Storage. Let’s pause and think through broadly what still needs to happen for your code to run:
-
Azure must allocate your application to a server with capacity.
-
The Functions runtime must then start up on that server.
-
Your code then needs to execute.
Steps 1 and 2, if done unintelligently can take a while, spinning up and configuring a server takes time. To make this experience better for users, instead of starting from scratch every time, we’ve implemented a way to keep a pool of servers warm and draw workers from that pool. What this means is that at any point in time there are idle workers that have been preconfigured with the Functions runtime up and running. Making these “pre-warmed sites” happen has given us measurable improvements on our cold start times. Things are now on the order of three to four times faster. Now, let’s go back and walk through a more detailed view of what happens when you trigger the execution of a function when resources haven’t yet been allocated.
What happens during a cold start
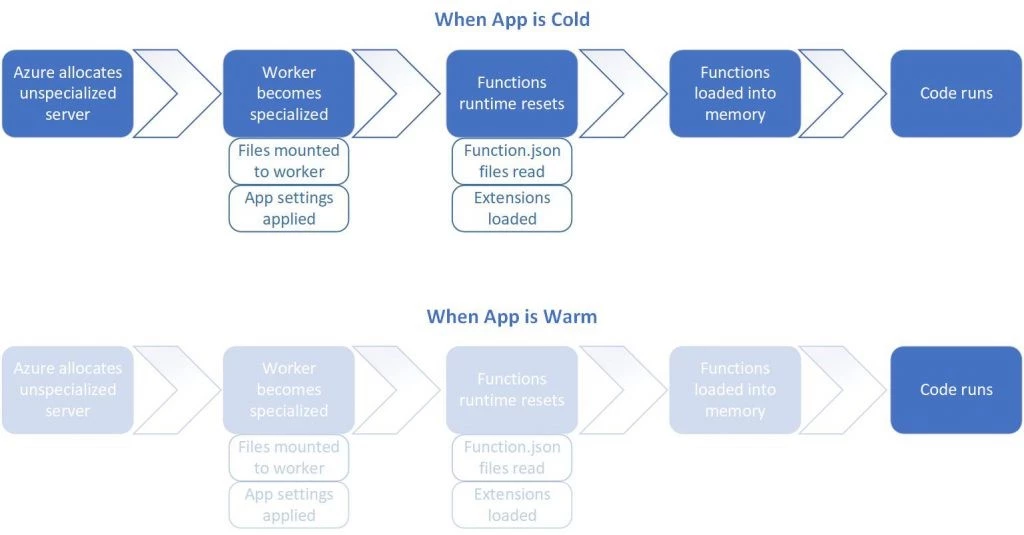
-
Azure allocates a preconfigured server from the pool of warm workers to your app. This server already has the Functions runtime running on it, but it is unspecialized.
- This worker becomes specialized by configuring the Functions runtime in ways that are specific to your app. A few things happen to do this specialization, including:
- The Azure Functions infrastructure mounts your Azure Files content to the worker you’ve been assigned
-
App settings specific to your function app are applied to the worker
- The Functions runtime resets, and any required extensions are loaded onto the worker. To figure out which extensions to load, the runtime reads the function.json files of any function in the function app. For instance, this happens if you’re using Durable Functions, or if you have input or output bindings.
- The Functions themselves are loaded into memory by language providers. This will take a varying amount of time based on the size of your application.
-
Your code runs.
If you’ve executed your function recently steps 1-4 have already happened, the resources are already allocated, and your site is warm. As you can imagine, in this scenario things are considerably faster. We deallocate resources after roughly 20 minutes of inactivity, after which your next call will be a cold start and this entire process will happen again. This is illustrated above.
Is the team making any more improvements?
Yes! This post is simply a point in time (February 2018) analysis of how things work, and many specifics are subject to change. As evidence, we recently released an update to the runtime and for our general availability languages we’re seeing a further 50 percent improvement on cold start times. I won’t go super deep on it here, but this update fixed a regression in our native image generation. For more details, read up on NGEN or check out the release itself, we are fully open sourced.
How can I improve my code to help avoid long cold starts?
Now that we have a baseline understanding of what’s happening behind the scenes to cause cold start, we can start to address how to architect your solutions to avoid it.
Language: First and foremost, use our generally available languages such as C#, F#, and JavaScript. We have several experimental languages which aren’t fully supported and optimized most of them actually spin up a new process on every execution, which impacts latency a great deal. Also, it’s important to note that any language running in our 2.0 runtime is in preview and also hasn’t been optimized fully. We expect these languages to perform better in the future, but for now, stick to the GA languages mentioned above. For more specifics, see our documentation.
Write lightweight code
Dependencies: When you deploy your code, your dependencies are added as files to your application. As outlined in step 4 above, all code needed by your app eventually gets loaded into memory, which takes longer with a larger application. So, if you have a ton of dependencies, you’ll get a longer cold start due to increased time for I/O operations from Azure Files, and longer time needed to load a bigger app into memory. This is a thing we see all the time for folks writing Functions in JavaScript, npm trees can get huge. Not only does this increase the size of your app, but also increases the number of files that Azure Files has to handle, which causes further slowdown. For this scenario in particular, we’ve released a tool to help. Check out Funcpack to learn more!
Efficient Code: Sometimes the answer is simply writing more efficient code. There are a few approaches to note here, first try to make as much processing as possible asynchronous. Functions won’t perform well if you have a heavyweight synchronous call blocking your code from completing. Along this vein, try to minimize the amount of work that has to happen before your code starts up and avoid code which consumes a lot of CPU. If you’re concerned about this yourself, we recommend trying out Application Insights. It’s a fantastic monitoring tool and can help isolate application slowdown from platform slowdown.
Avoiding cold start altogether
Dedicated Mode: As mentioned before, running Functions in an App Service Plan alleviates these issues since you control what happens on your VM. This is slightly more expensive, and isn’t serverless, but if your solution has a hard requirement for low latency on every individual call, consider using the Dedicated mode.
Feedback
Feedback is always welcome. If you want to tell us what you think or reach out to the product team directly for any other reason, engage with us on Twitter or GitHub!