Storm介绍
Apache Storm是一个分布式的,容错的,开源的计算系统。它允许我们使用Hadoop来进行实时数据处理。Storm的解决方案还能保证数据都被处理,它有能力对首次处理不成功的数据进行重新处理。根据一些性能方面基准测试,Storm可以达到每个节点每秒处理超过百万的Tuple。
那么为什么要用HDInsight里的Storm呢?在HDInsight服务里的Apache Storm是一个整合在Azure环境里的托管的集群。它提供了几个主要好处:
- 作为一个托管服务,它能够达到三个9 (99.9%)的高可用性
- 它支持使用各种语言, Java, C$, Python等等。还可以混合语言,比如读的时候用Java,处理的时候用C#. 它使用了Trident的Java接口来创建Storm Topology,支持“有且唯一”的消息处理,事物性的数据存储持续化,和一组通用的流分析的操作。
- 它提供了内建的动态扩展特点, 对一个HDInsight的集群进行扩展不会影响执行Storm Tology。
- Storm和其他Azure服务整合在一起,包括Event Hub,Azure Virtual Network, SQL 数据库, Blob storage, 和Document DB。可以用Azure Virtual Network把多个HDInsight Cluster能力整合起来,创建使用HDInsight HBase或者Hadoop的分析流水线。
HDInsight上的Storm非常容易准备,我们可以通过Auzre门户或者PowerShell来创建,只需要选取简单的几个参数,等上15分钟就可以创建完毕。如果我们使用Visual Studio, 那么HDInsight Tools for Visual Studio可以用来创建C#或者混合C#/Java的topology,然后提交到HDInsight集群中的Storm。HDInsight Tools for Visual Studio还提供了接口来监视和管理Storm topology。
每个HDInsight集群里的Storm都提供了一个基于Web的仪表盘,我们可以用它来提交,监视,和管理所运行的Storm topology。Storm还通过Event Hub Spout提供了跟Azure Event Hub集成的功能。
Storm可以保证每个收入的消息都被完全处理,即使数据的分析分散到几百个节点。
Storm是跑在Hadoop的Yarn框架上的应用。同Hadoop的Job Tracker类似,Nimbus 节点提供了类似的功能,它可以通过Zookeeper来把任务分配到其他节点。Zookeeper节点提供集群的协调并且提供Nimbus和工作节点上的Supervisor进程的通讯。如果有处理节点坏掉了,Nimbus会被通知到,然后它会把任务和相关数据交给其他节点来处理。缺省设置下Apache Storm有单个Nimbus节点,而HDInsight里的Storm有2个Nimbus节点。如果主节点失败了,集群会切换到从属节点。现在HDInsight支持动态调整工作节点的数量,就算是在处理数据的时候也可以进行动态调整。
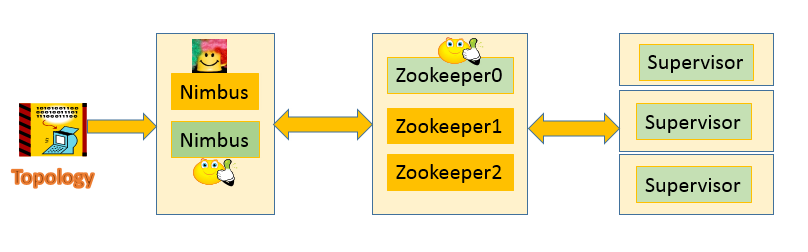
那么Storm是如何来处理数据的呢?
我们知道Hadoop是运行MapReduce作业的,而Storm是运行topology的。Storm集群包括2类节点:运行Nimbus的主节点,和运行Supervisor的工作节点。
Nimbus是什么?它类似于Job Tracker, 主要负责把代码分发到集群中,把任务派发给虚拟机,然后监控是否有失败的状态。
Supervisor呢?它运行在每个工作节点,负责启动和停止工作进程。
工作进程执行topology的一部分。一个运行的topology会被分布到很多个工作进程。
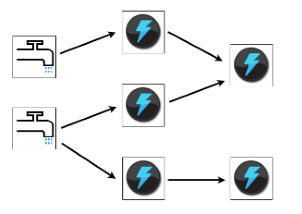
Topology定义了对数据流处理的计算图,也就是一个逻辑上的拓扑结构。不像MapReduce的作业,topology作为一个实时在Storm中运行的单位,会一直运行直到我们停止它。
在Storm里的Stream(流)是Tuple的集合。流是由Spout和Bolt来生成的,而由Bolt来消费。
那Tuple又是什么呢?Tuple是消息传递的基本单元,一个带类型的值的已经命名的表。我们可以想象Key-Value的配对,在这里因为字段名称已经事先定义好了,所以只需要值的列表就可以了。
Spout是产生源数据流的组件,通常我们用它来从外部数据源读取数据,然后发射为数据流。
Bolt呢?它是用来消费数据流的,提供对Tuple的处理,并且也可能发射数据流。我们可以在Bolt对数据进行想要的操作。Bolt也负责把数据写到外部存储,比如queue,HDInsight,HBase,Blob或者其他数据存储。
另外Apache Thrift是为了可扩展的跨语言服务开发的一个软件框架,使得我们可以通过它在C++, Java, Python, PHP, Ruby, Erlang, Perl, Haskell, C#, Cocoa, JavaScript, Node.js, Smalltalk, 和其他语言间创建服务。Nimbus是一个Thrift的服务, 而topology是一个Thrift的定义,所以我们可以使用不同语言来开发Topology。
一个基本的Storm可以保证至少一次的处理,而Trident可以保证有且唯一次的处理。在流处理中通常有几种处理的模式。比如读取输入Tuple,发射0个或多个Tuple, 然后在执行最后回应输入tuple。这类模式可以用IBasicBolt来自动化。而Join的处理模式可能有不同的方式。比如,我们可以把多个流的每个tuple join起来成一个新的流。或者只join某个时间窗的一批tuple。这些都可以通过fieldsGrouping来实现。我们有时候会用这个办法来定义tuple如何引导到bolt。Batching模式可以通过集中方式来实现,比如在基本的Storm Java Topology里,我们可以用一个计数器来批处理X条tuple, 或者通过一个”tick tuple”来每X秒发射一个批次。Caching是可以加快处理速度的,我们可以考虑使用fieldsGroup来提高Cache lookup的命中率,使得包含field的tuple都会进到同一个进程里,这样可以避免不同进程间的重复的Cache。对于获取Top N的计算,我们可以并行计算top N,然后合并输出到一个全局值。我们可以用fieldsGrouping来导引到并行的Bolt上,使得数据根据字段值进行分区,然后引导到一个bolt再做全局的top N。