浅析微软大数据平台HDInsight (4) 分布式文件系统(下)
上一章我们探讨了Hadoop中的Windows Azure Blob Storage文件系统的基本结构,本章我们主要来探讨微软Windows Azure Blob Storage文件系统的高可用性和负载均衡。
写的一致性和高可用性
所有的写,都是在log的最后扩展下去的。它是扩展在那个log的最后一个extent的后面。
它做到了数据写的一致性。我们来看看它是如何达到一个extent的复制能保证写的一致性的:
首先它保证extent的append的顺序在3个replica上是一样的。
只有三个replica上的append操作都被提交到存储,这时才算这个写操作是成功的。
当extent达到某个大小限制,或者写失败了,它会把这个extent的所有replica都封存起来, 不再继续扩展写入任何数据。
当写失败了,它会把这个正在写的extent的三个复制品都封存起来。然后它会把这个extent写到其他的节点上,同样复制成3份在不同的其他节点上。然后,它把这个extent记到对应的分区的log的最后。
然后它会把标记为失败的节点所对应的replica set里再复制一份到另外一个节点上然后原来这个失败的节点就不用了。
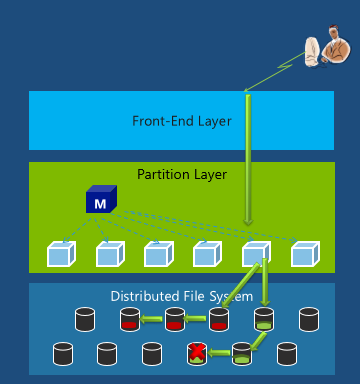
Partition分区层次的动态负载均衡
分区层次把索引和事务处理分布到所有分区服务器上。有一个Master会监控所有分区服务器上的交通负载和资源的使用情况,动态地进行分区服务器的负载均衡从而实现更好的性能和可用性。
比如有一个请求是到某个分区服务器,而发现这个分区服务器资源不够或者负载太高了,那这个时候索引会被动态的转移到另外一个分区服务器,然后请求通过那个分区服务器发送到下面的分布式文件系统层。
可以看到在分区这一层,数据并不被移动。在动态调整中调整的只是哪个分区负责哪段索引。
分布式文件系统层次的动态负载平衡
对于读的负载平衡,是在3个复制品之间的行为,它会监控每个节点的负载和延迟来动态选择从哪个复制品来读, 而当读超过了延迟时间的95%它就会发起额外的并行读。
对于写的负载平衡,它会监控每个节点的延迟和负载。如果写的时候某个节点出现负载过重,就相当于失败,那么它会把这一组复制品都封存起来,然后切换到另外一组节点上扩展新的extent。
对于容量的负载平衡,它有一个后台的虚拟化存储机制能够慢慢地动态的移动复制品,使得磁盘和节点都有同样的容量。这一点非常重要,因为这能够避免某个节点或者磁盘变成所谓的热节点,热磁盘。
从Azure Blob Storage的详细机制,我们可以看到其实Windows Azure storage也提供了相当不错的容错机制,并且具有动态负载均衡,有高可用性。可以说它提供了HDFS部分的功能,与HDFS有异曲同工之妙。如果把它作为存储,而为HDFS框架服务,那么将会是不错的选择。
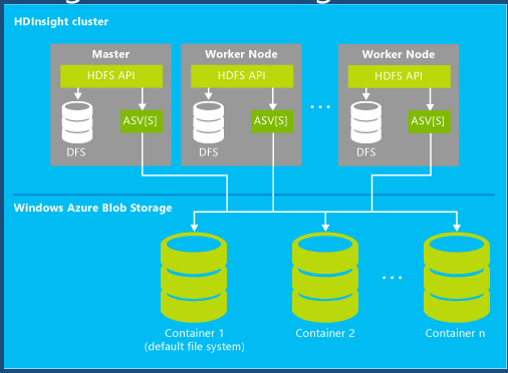
下图展示了HDInsight Service是如何把Windows Azure Blob Storage整合到这个架构里面的。HDFS框架提供的应用程序接口依然没有任何变化,只不过它把原来的分布式文件系统延展到了Windows Azure blob storage。用Windows Azure blob storage替代了每个节点的本地磁盘。