浅析微软大数据平台HDInsight (3) 分布式文件系统(中)
上一章我们探讨了Hadoop中的HDFS文件系统,本章我们主要来探讨微软HDInsight平台特有的Windows Azure Blob Storage文件系统。
说到WABS,我们首先解释下什么叫BLOB.
所谓的Blob,就是Binary Large Object,二进制大对象。在Windows Azure的存储上面,把这种二进制大对象具体分为2种。
一种被称为Block Blob,以块为单位的Blob。它主要是为了stream一类的负载服务的。
每个Blob由一组有顺序列表的块组成,最大的Blob大小为200GB。
在更新的时候它是基于事务提交的。它在上传的时候是以块为单位上传的,可以是并行传输很多个块。而当上传以后,要通过一个所谓的Commit阶段,把所有的块整理成一个列表,然后才把所有的块合起来,这个才算完成提交。
在读取Block Blob的时候,读取范围可以是从Blob任何一个字节的偏移量开始。
第二种Blob叫做Page Blob,就是以页为单位的Blob,它是针对随机写入操作的负载。
每个Blob包括一个页的索引数组。最大的Blob大小为1TB。它是立即更新的,不需要Commit这样的步骤。它的读范围也是可以从任何一个字节的偏移量开始。
通常我们定义一个Windows Azure的Storage对象名字, 我们会以3个部分来确定。
首先是Account。我们创建一个Windows Azure的Storage都会生成一个Account。
然后在这个Account下面,对于Blob类型我们可以有多个Container。所以我们要指定container的信息,然后再指定我们blob的名字。
另外Windows Azure Storage还包括其他类型的对象,比如Table, 或者Queue。
如果我们要去访问某个container上的blob对象,我们可以用https://后面跟上我们的storage名字,然后加上”.blob.core.windows.net”然后用斜杠分割指出container的名字。
https://<accountname>.blob.core.windows.net
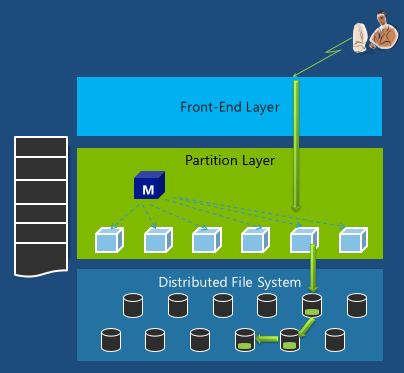
Windows Azure Storage Stamp
通常一个Storage Stamp包括几个层次: Distributed File System分布式文件系统层次,Partition分区层次,和前端层次。在前端通常还有负载均衡的部分。
当用户访问一个storage的时候,通常是由负载均衡部分入口,然后走到下面的几个层次 然后再回上来最后返回到客户端。
那不同的数据中心可以有同一个storage的stamp, 那这时就是通过storage location service来协调管理。我们可以对Stamp之间互相进行复制, 这被称为Geo replication, 就是跨数据中心的复制。
我们来进一步看看Stamp里面的架构。
首先最底层是分布式文件系统的层次。
数据在这里被写入磁盘并作复制, 数据是以extent为单位存储的,每个extent被存成为一个文件,一个extent会被复制成3个拷贝分布在不同的节点上(这个跟HDFS其实很像)。另外这个文件系统只能做Append。
中间这个层次是分区层次。这个层次理解我们数据的抽象状况,并且提供优化的并发访问。它有大量可扩展的索引。它有所谓的log structured merge tree,也就是log的结构化的混合树状结构,每个log(stream)都是一个extent的链表。
在上面是前端层。它提供了REST的编程接口,还提供用户认证,以及记录操作的日志等功能。
那当一个用户发送了请求写入数据,那这个数据经由上面2个层次最终到达分布式文件系统层次,它被复制成了3份。