浅析微软大数据平台HDInsight (2) 分布式文件系统(上)
在HDInsight中,微软提供了两种文件系统。
在On premise版本的HDInsight中,也就是HortonWorks Data Platform for Windows中,以及Parallel Data Warehouse中的HDInsight region中,微软提供了Hadoop的HDFS作为文件系统。
在Windows Azure HDInsight Service中,微软提供了Windows Azure Blob Storage,又被称为Azure Storage Vault作为缺省的文件系统。在文件系统的接口上面,它仍然沿用了Hadoop Distributed File System的接口。因此在使用上同HDFS是一致的。
本章我们主要来探讨HDFS这个文件系统。
HDFS的定义是,它是为存储非常大的文件而设计的。它通常运行在一个以普通硬件组成的群集当中,访问数据通常是以流的方式进行访问的。
那这里有是三个关键字,也显示了HDFS的特征:
第一个关键词,Very large files, 它可以存储非常大的文件,从GB, TB直到PB的大小。
第二个关键词, Streaming data access, 这种流数据访问,是指一次写入 多次读取的访问。而读取的时候,往往是读取整个数据集。
第三个关键词,Commodity hardware, 也就是非常普通的硬件资源。它可以是不同厂家的硬件,平民的价格。因为硬件个体本身不需要高可用性,高容错的机制,那么在集群中节点失败的可能性就非常的高。
HDFS目前来说还不是一个非常理想的文件系统。如何理解这个观点呢。它其实有以下几个弱项:
第一个弱项是对低延迟的数据访问它无能为力。
HDFS是专门为数据的大吞吐量优化的,整批数据的吞吐量是高的。但是由于采用的硬件并不高端,响应读写请求不能非常快。
用Hbase这个nosql的数据库可能是一种选择。
第二个弱项是如果有很多的小文件,它就显得捉襟见肘了。
在HDFS的文件系统中,每个文件,目录和块会占用150字节左右作为namespace需要的信息。
NameNode(命名节点)上把文件系统的metadata都载入在内存里。如果文件很多很多,那么会导致NameNode占用大量内存,受到硬件容量的限制。
第三个弱项是如果要多个写入者,随意的文件修改,那么它就无法胜任了。
目前HDFS还是单个写入者。而写入总是在文件的结束位置进行的。
HDFS基本概念
Block (块)
这个是文件系统最小的访问单位。定义这样一个最小访问单元是为了减少磁盘寻道的消耗。
通常磁盘的block是以512个字节为单位。在操作系统的文件系统上的block是磁盘这个block的整数倍。而HDFS的block是以操作系统上的文件系统的block的整数倍。通常这个缺省的大小是64MB。
Namenode和Datanode
NameNode上存放的是什么? 是namespace的镜像,也就是文件系统的命名空间。还包括修改的日志。
DataNode上存放的就是文件的blocks。
那么如果NameNode失败有什么机制可以恢复呢?
NameNode是单个节点的,或者2个节点的(包含Primary和Secondary)。Name Node可以把状态写到多个文件系统上,比如本地磁盘加上远程的文件系统。而secondary的namenode,又叫做backup node会根据修改的日志把namespace命名空间的镜像混合起来,保存一个副本。当Primary节点失败,可以把metadata文件拷贝到secondary上然后把secondary运行成primary。
文件的划分
为了形象地说明文件的划分,我们来举一个例子。
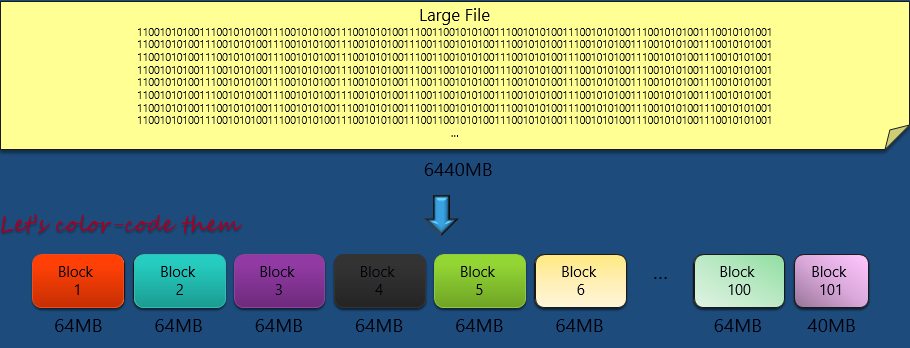
在这个例子中,我们有一个很大的文件,文件的大小是6440MB。非常大的一个文件。
我们之前提到过,HDFS上的文件block缺省是64MB,所以我们按照64MB大小来划分这个文件。那么我们就会分成 101个block,前一百个都是64MB,而最后一个,也就是Block 101 是40MB。
每个Block会当作操作系统上的一个具体的文件存在。比如在Windows系统上是存放在本地NTFS上的。
接下去我们把每个block涂上颜色来做区分。
我们假设有5个数据节点,而我们设置的replication factor为3。
那么我们把前面分出来的block一个个进行分布。Block1将会被分布在Node1,Node2和Node4上。
Block2会被分布到Node2, Node4和Node5上。
Block3会被分布到Node1, Node3和Node4上。
我们知道每一个文件block会有三份拷贝,它们给分布到不同的Node, 但是究竟分布到哪一个Node有没有什么讲究呢?
那缺省的规则是这个样子的:
- 第一个拷贝会被放到那个开始生成这个文件的节点上。这个被称为Write Affinity。
- 第二个拷贝会被放到和第一个拷贝同一个Rack的另外一个节点上, 也就是同一个机柜中另外一个节点。那我们知道数据节点可以有几十个甚至上百个,通常情况下他们会放到几个机柜里。而通常机柜里的节点之间的网络连接由于距离短,可能用的网络连接设备也比较快。那在同一个机柜里的传输通常效率比较高。而如果是跨机柜的话,可能效率会低。因此第二个拷贝会被优先放到同一个机柜里。
- 第三个拷贝会被放到另外一个机柜里的一个数据节点上。这样做的考虑是为了达成容错。比如说一个机柜的交换机坏掉的情况下,只能通过从另外一个机柜才能访问数据。
那从这里可以看出,之所以有这样的文件block的拷贝规则,它的目的就是为了达到:
1. 负载均衡lload balance。取block1, block2, block3可以在不同的Node上取,分担了workload。
2. 快速的访问(fast access)。有数据请求尽量能够在同一个机柜里进行访问。
3. 容错(fault tolerance)。通过数据块的冗余,在数据节点失败的情况下,能够切换其他的节点获取同样的数据,不影响访问数据。
NameNode同所有的DataNode的通信主要是为了传递HeartBeat, 从而知道如何在Data Node上做负载均衡,另外知道如何对文件block进行复制。
而每个DataNode它会同自己的本地磁盘打交到,把文件块内容写到自己的磁盘上。
容错
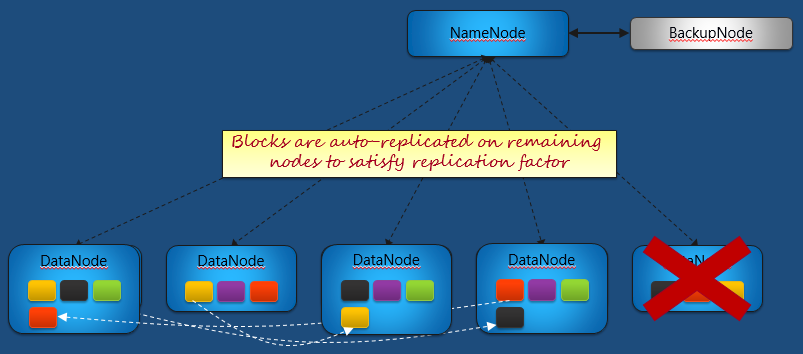
DataNode会给NameNode隔一段时间发一个心跳信号,NameNode如果收到信号就说明DataNode活着。如果说NameNode发现某一个DataNode没有心跳了,那么它就认为那个DataNode出问题了,也就是失败了。
那这个时候我们不用担心,因为所有存放在这个DataNode上的文件块都有另外的备份,他们被分布在其他可用的DataNode上面。根据Replication Factor我们知道有多少个剩下的拷贝。
但是这并不是一个可持续的状况,我们必须根据replication factor继续生成下一个拷贝才能保证下下次再有DataNode失败的时候我们还能够有节点可以返回文件块,维系下去。所以,我们要在本次DataNode失败发生的时候,就立刻开始复制。于是,你看到黑色的文件块被又复制到另外一个本来不存在该文件块的一个DataNode上。
同样,红色文件块被复制到了另外一个DataNode上。
而黄色文件块呢,也一样被重新复制了一份到另外一个DataNode上。
那复制完成以后,这就恢复到了初始的分布状态,只不过我们少一个节点而已。
横向的扩展和重新负载均衡
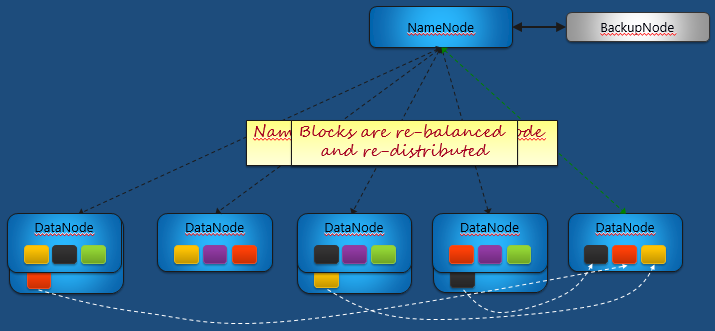
如果我们增加了一个DataNode,这时NameNode会探测到有一个新的DataNode加进来了。这时NameNode会重新调整分布和负载均衡的情况。它会从文件块较多的DataNode上把文件块给转移到新的节点上。
那这个时候比如原来第一个节点上的红色文件块就被转移到这个新的节点上。
而类似的,第四个节点上的黑色文件块也被转移到新节点上。
而第三个节点上的黄色文件块也被移到了新节点上。这样每个节点都有3个文件块了,这个分布就很均匀了。