AzureML中的聚类
聚类是一种无监督的机器学习。在聚类中,目标是为了把相似的对象归组到一起。通常聚类算法可以分成以下几类:
- Partitioning分区:可以把数据集分成k个分区。每个分区对应于一个簇。
- Hierarchical 分层:基于数据集,分层会通过自下而上或者自上而下地创建簇。在自下而上的方式中,算法开始把每个项分派给一个簇,在算法从层次网上移动的时候,它把个别相似的簇归并成更大的簇。这样一直继续下去知道所有的簇都归并到一个也就是层次的根节点。在自上而下的方式中,算法是把所有项目都归于一个簇,然后在每次反复的时候分成小的簇。
- Density 密度:该算法考虑邻居的密度,也就是项目数量。通常它用来找出有任意形状的簇。相反,分区依赖于距离的度量,所以生成的簇有普通的形状,比如球状。
在基于分区的聚类算法中,我们需要度量点和向量的距离。通常的度量方式有欧式距离,余弦距离,曼哈顿距离等等,在Azure Machine Learning中,K-Means Clustering支持欧式距离和余弦距离的度量。对2个点p1, p2来说,欧式距离就是这两点连线的线段长度。欧式距离也可以度量两个向量的距离。而对2个向量v1和v2来说,余弦距离就是v1和v2的角度的余弦。
在聚类时使用的距离度量取决于聚类数据的类型。欧式距离对向量的度量量级是敏感的。比如说,尽管2个向量看上去很相似,特征的数量级会影响欧式距离的值。在这种情形下,用余弦距离可能更合适,因为余弦距离对数量级不敏感。2个向量之间的余弦角度是很小的。
Azure Machine Learning中使用K-Means算法来聚类。这个算法过程是这样的:
- 从数据集随机选取k个项目作为初始中心。
- 对剩下的其他项目,根据项目和簇中心的距离把他们分配给对应的簇。
- 重新计算每个簇新的中心。
- 重复步骤2和步骤3直到簇不再发生变化或者达到了最大的重复数。
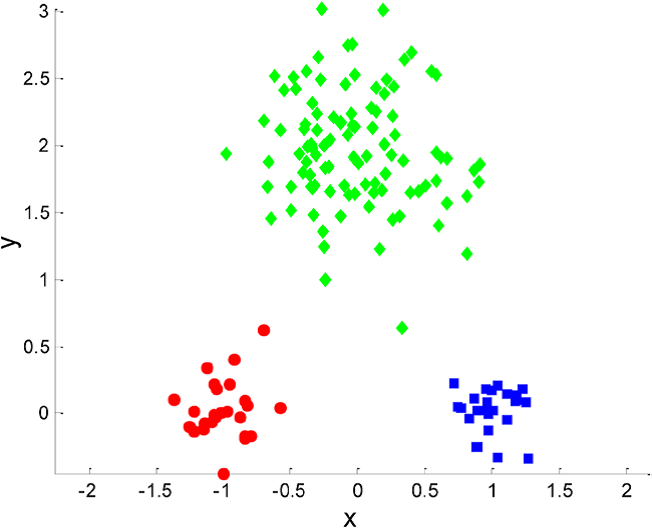
如图所示,这是一个K-Means的聚类,这里分成了3个簇,用三种颜色来标明。
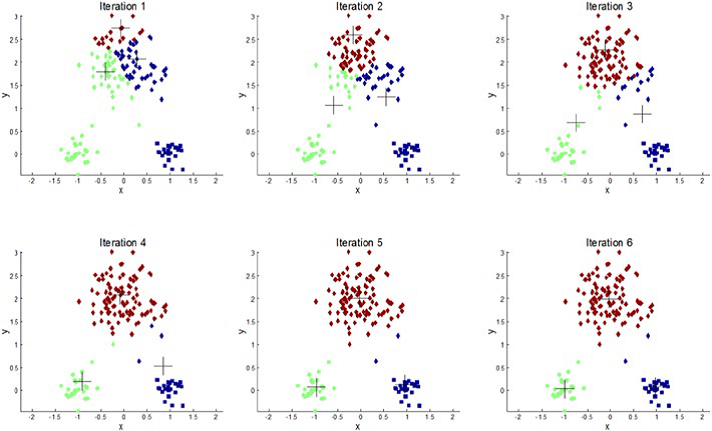
如图所示,这是对于k=3的时候算法计算的过程。+号是每次计算的簇的中心。一次次降低了平均误差平方根变得越来越准确反应簇的中心。
在K-Means Clustering模块中,它支持不同的簇中心的初始算法。这是通过Initialization属性来设置。我们可以用下面5种初始算法:
- Default缺省的,就是选取起始的N个点作为初始中心。
- Random随机的,随机选取初始中心。
- K-Means++ 采用K-Means++的中心初始化。
- K-Means+Fast 在每次重复中选取最远的中心作为初始中心。
- Evenly 选取均匀的N个点作为初始中心。