SQL Server 2012新performance counter:非常实用的Batch Resp Statistics
SQL Server 2012引入了一个新的performance counter, Batch Resp Statistics。这个counter的目的是“to track SQL Batch Response times”。这个counter下面有好几档如下:
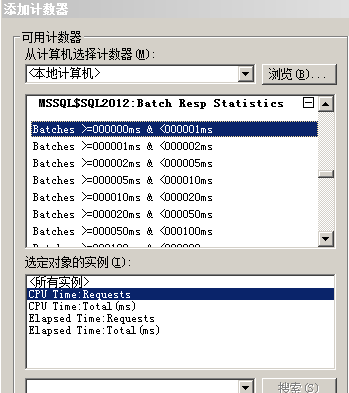
具体就是:
Batches >=000000ms & <000001ms
Batches >=000001ms & <000002ms
Batches >=000002ms & <000005ms
Batches >=000005ms & <000010ms
Batches >=000010ms & <000020ms
Batches >=000020ms & <000050ms
Batches >=000050ms & <000100ms
Batches >=000100ms & <000200ms
Batches >=000200ms & <000500ms
Batches >=000500ms & <001000ms
Batches >=001000ms & <002000ms
Batches >=002000ms & <005000ms
Batches >=005000ms & <010000ms
Batches >=010000ms & <020000ms
Batches >=020000ms & <050000ms
Batches >=050000ms & <100000ms
Batches >=100000ms
这些档的含义是怎样的呢?假定对于Batches >=010000ms & <020000ms,它的含义是这样的:
1) 如果batch (也就是一个request)的执行时间是10000ms 到20000ms之间的则计数
2) CPU time 和Elapsed time 的含义和sys.dm_exec_requests 里面的含义一致。 CPU time 就是 “请求所使用的 CPU 时间”, Elapsed time 就是“请求到达后经过的总时间”。 简单说,CPU time就是batch request的CPU指令真正执行的时间,而Elapsed time 是指CPU时间加上等待的时间。比如当batch等待磁盘I/O,等待锁(就是被阻塞了)的时候,Elapsed time就一般比CPU time 长。这里注意的是因为并发执行的关系,Elapsed time 有时候并不会就恒等于CPU time 加上等待时间,而是应该有些出入。
3) CPU time:Requests 指CPU time 在这个范围内的batch request的总数。CPU time:total(ms)指CPU time 在这个范围内的时间总和。Elapsed time:request 和 Elapsed time:requests 的含义类似。
4) 这些counter的值是累计的。也就是说,会一直增加,直到SQL server 重启。
为了测试这个counter,我使用ostress.exe测试工具。这个工具可以产生指定数目的连接,反复执行指定的脚本。我的测试脚本如下:
1. 首先建立测试的表
USE[Test_good]
GO
/****** Object: Table [dbo].[test] Script Date: 2012/12/26 14:57:56 ******/
DROPTABLE[dbo].[test]
GO
/****** Object: Table [dbo].[test] Script Date: 2012/12/26 14:57:56 ******/
SETANSI_NULLSON
GO
SETQUOTED_IDENTIFIERON
GO
SETANSI_PADDINGON
GO
CREATETABLE[dbo].[test](
[colid][int]IDENTITY(1,1)NOTNULL,
[col2][varchar](400)NULL
)ON[PRIMARY]
GO
SETANSI_PADDINGOFF
GO
2. 然后插入上千万的记录。

3. 然后使用如下的脚本测试。为了让测试更有趣,我在语句里面使用了rand()函数,以及动态判断是否需要人为的delay (见waitfor delay 语句)2秒钟:
usetest_good
go
declare@col1int=rand()*10000
declare@col2int=rand()*100000
declare@tint
if (@col1>@col2)
begin
set@t=@col1
set@col1=@col2
set@col2=@t
end
begintran
updatetestsetcol2=getdate()wherecolid=(@col1+@col2)/2
declare@iint=rand()*100
if (@i>50)waitfordelay'00:00:02'
committran
select@col1,@col2
select*fromtestwherecolidbetween@col1and@col2
go
select 1
declare@iint=rand()*100
if (@i<30)waitfordelay'00:00:02'
go
select 2
go
declare@iint=rand()*100
if (@i>30)waitfordelay'00:00:02'
go
测试的结果如下:
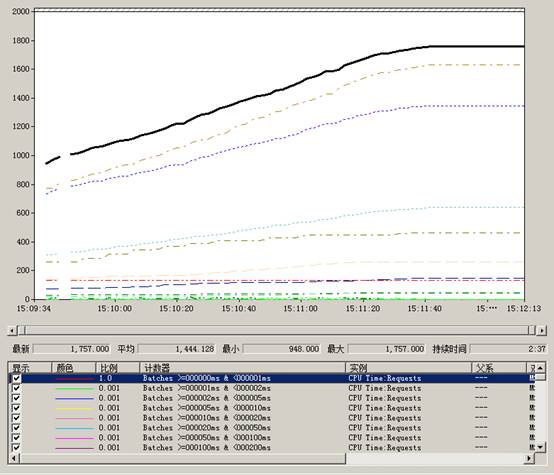
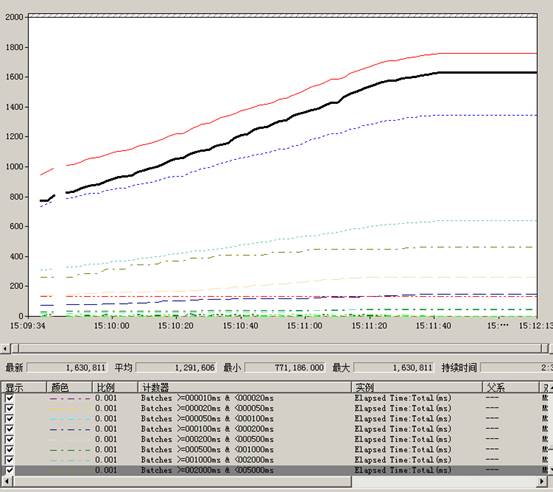
从这个可以看出:
系统的语句主要分为几类(按照Elapsed time):
Batches >=000000ms & <000001ms 672次
Batches >=002000ms & <005000ms 309次
如果觉得上面的图形看起来不够直观,那么还可以使用下面的语句来得到更方便阅读的结果:
(注:语句来自Neil Hambly)
sELECT[counter_name],"CPU Time:Total(ms)","CPU Time:Requests","Elapsed Time:Total(ms)","Elapsed Time:Requests"
FROM (SELECT[counter_name],[instance_name],[cntr_value]FROMsys.dm_os_performance_countersWHEREOBJECT_NAMELIKE'%Batch Resp Statistics%')os_pc
PIVOT(AVG([cntr_value])FOR[instance_name]
IN("CPU Time:Total(ms)","CPU Time:Requests","Elapsed Time:Total(ms)","Elapsed Time:Requests"))ASPvt;
结果如下:
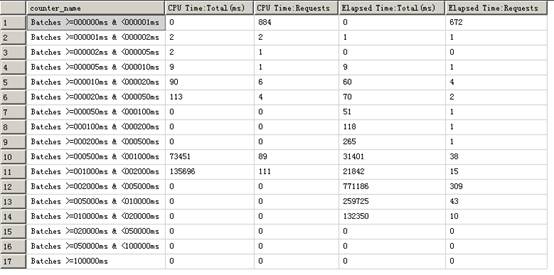
这个结果一目了然:
1) 你可以看到系统所有语句的响应时间的分布情况,真正体现了这个counter 的 resp statistics 的字面含义,也即系统batch request的响应时间统计信息。
2) 你很容易知道系统的大部分的语句的响应时间和语句的总数
3) 通过比较CPU time 和Elapsed time的差异,你很容易知道batch request 是否经常因为等待(如等待I/O,阻塞等)而导致长的执行总时间。