SQL Server中SCAN 和SEEK的区别
SQL SERVER使用扫描(scan)和查找(seek)这两种算法从数据表和索引中读取数据。这两种算法构成了查询的基础,几乎无处不在。Scan会扫描并且返回整个表或整个索引。 而seek则更有效率,根据谓词(predicate),只返索引内的一个或多个范围内的数据。下面将以如下的查询语句作为例子来分析scan和seek:
select OrderDate from Orders where OrderKey = 2
Scan
使用Scan的方式,SQL Server 会去读取Orders表中的每一行数据,读取的时候评估是否满足谓词 “where order=2”。如果满足(数据行符合条件),则返回该行。这个例子里,我们将这个谓词称作“residual predicate”。为了得到最优的性能,SQL会尽可能地在扫描中使用“residual predicate”。但如果residual predicate的开销过于昂贵,SQL Server可能会使用单独的“filter iterator”. “residual predicate”以where关键字的形式出现在文本格式的plan中。对XML格式的plan,则是<predicate>标记的形式。
下面这个扫描的文本格式的plan的结果:
|--Table Scan(OBJECT:([ORDERS]), WHERE:([ORDERKEY]=(2)))
下图说明了扫描的方式:
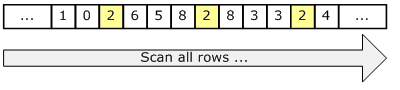
无论数据行是否满足条件,扫描的读取方式都会访问表中的每一个数据,所以scan的成本和表的数据总量是成比例的。 因此,如果表很小或者表内的大多数数据多满足谓词,scan是一种有效率的读取方式。然而如果表很大或者绝大多数的数据并不满足谓词, 那么这种方式会让我们访问到太多不需要的数据页面,并执行更多的额外的IO操作。
Seek
继续以上面的查询为例子,如果在orderkey列上有一个索引,那么seek可能会是一个好的选择。使用seek的访问方式,SQL Server会使用索引直接导向到满足谓词条件的数据行。 这个例子里,我们将这个谓词称为“seek predicate”。 大多数情况下,SQL Server不必将“seek predicate”重新评估为“residual predicate”。 索引会保证“seek”只返回符合条件的数据行。“seek predicate”以seek关键字的形式出现在文本格式的plan中。 对于xml 格式的plan,则以<seekpredicates>标记出现。
下面是使用seek的文本格式的plan的结果:
|--Index Seek(OBJECT:([ORDERS].[OKEY_IDX]), SEEK:([ORDERKEY]=(2)) ORDERED FORWARD)
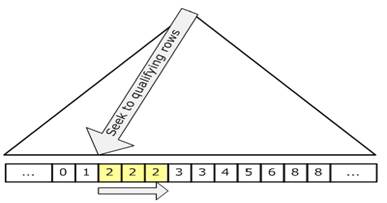
使用seek时,SQL Server只会直接访问到满足条件的数据行和数据页,因此它的成本只跟满足条件的数据行的及其相应的数据页面数量成比例, 和基表的数据量完全没有关系。因此,如果对于一个选择性很高(通过这个谓词,可以筛选掉表中的大部分数据)的谓词条件,seek是非常高效的。
下面的表格列出了seek和scan这两种查找方式和堆表,聚簇索引和非聚簇索引的各种组合:
| Scan | Seek | |
| Heap | Table Scan | |
| Clustered Index | Clustered Index Scan | Clustered Index Seek |
| Non-Clustered Index | Index Scan | Index Seek |