Hierarchies (trees) in SQL Server 2005
There is much debate about how to implement hierarchies (trees) relationally in SQL Server. I decided to test the main techniques out and see which performed best for my application.
My problem is efficiently representing hierarchies in an experimental application code analysis database. The main hierarchy I am interested in is the class hierarchy. I want users to be able to determine quickly all the subclasses of a class. Class hierarchies tend to be broad and shallow. Since the .Net framework has about 18 500 classes (counting compiler generated classes) creation and query performance is an issue. In addition, since developers will be creating custom reports over the database, ease of query construction (queriability) is an issue.
There are three standard techniques for representing hierarchies in relation stores: the adjacency technique, the path technique, and the nested sets technique. A fourth approach based on floating point intervals (nested intervals) is sometimes mentioned but it is equivalent to the nested set approach with gaps and too hard for my users to understand.
Adjacency technique
In this representation, rows contain the IDs of their corresponding parent row. For example, the organization chart:
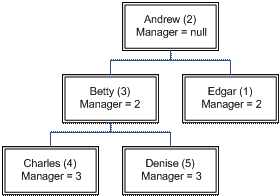
would be represented as:
Id |
Name |
Manager |
1 |
Edgar |
2 |
2 |
Andrew |
null |
3 |
Betty |
2 |
4 |
Charles |
3 |
5 |
Denise |
3 |
This is the first representation many people think of and is often considered a poor practice. However, many operations are straightforward to implement and users can easily understand it.
Path technique
In this representation, rows contain the path to their parents. For example, the organization chart:
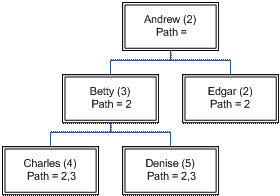
would be represented as:
Id |
Name |
Path |
1 |
Edgar |
2 |
2 |
Andrew |
|
3 |
Betty |
2 |
4 |
Charles |
2,3 |
5 |
Denise |
2,3 |
This makes queries like finding all the descendents of a node straightforward since you only need to look for all nodes with the appropriate path prefix. Because of index limitations, the trees cannot be too deep since to be efficient you need to index the Path column, which in SQL Server 2005 must be at most 900 bytes.
Nested sets
This is the approach championed by the indomitable Joe Celko (see 1, 2, 3 and 4). Essentially the idea is to label nodes with their left and right traversal ranks as a node is entered and exited respectively. For example, the organization chart:
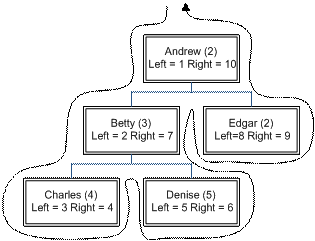
would be represented as:
Id |
Name |
Left |
Right |
1 |
Edgar |
8 |
9 |
2 |
Andrew |
1 |
10 |
3 |
Betty |
2 |
7 |
4 |
Charles |
3 |
4 |
5 |
Denise |
5 |
6 |
The representation makes operations like determining the descendents of a node and if two trees overlap easy because the left and right values bracket the left and right nodes of every descendent node.
The fundamental issue with the nested sets approach is that adding a node is very expensive (O(n)) since all subsequent nodes need to be renumbered.
Performance
Table 1 shows a simple benchmark for my problem involving 20 000 nodes. First the tree is created as 20 000 inserts and then the list of dependent nodes is generated for each of the 20 000 nodes in the tree. As expected, the adjacency technique works best for creating the tree. However, the surprising winner for finding all descendents of every node is also the adjacency technique.
Table 1 Time to create a 20 000 node tree and find all the descendents of each of the 20 000 nodes.
Technique |
Create (secs) |
All Descendents (secs) |
Adjacency |
4 |
4 |
Nested set |
6072 |
43 |
Path |
6 |
337 |
At first, I suspected a bug but my testing showed that all the techniques produce identical results. SQL Server 2005 does a good job of generating query plans for recursive CTE expressions but I think that because the whole table lives in cache and the tree is shallow (a maximum of 8 nodes deep) SQL Server can be very fast. It is also a great example of the power of the relational model since the result set is created in a highly parallelizable breadth-first way. As is often the case, a naïve implementation is faster because the runtime can optimize it better.
Because of the adjacency technique’s superior performance (for my shallow and broad trees) and queriability it is the most attractive choice. With more work I could probably improve the performance of the other techniques but the adjacency method has the performance and queriability I need. However, I am interested in any feedback you may have on issues I have missed.
Implementation experience
I found all three approaches easy to implement. The only time I had to think about what I was doing was figuring out what the best way to test for a varbinary prefix (I represented paths as strings of 4 byte node IDs). I am no T-SQL guru so I imagine any competent T-SQL developer could easily implement any of the approaches.
XML columns
The obvious SQL Server 20005 alternative is to encode the hierarchy in an XML column. Because classes are likely to relate to many other objects in the system, query patterns over classes are unpredictable and relational implementation performance is acceptable, I decided a pure relational implementation would give users the most power.