XML Document Property Parsing in SharePoint (2 of 5): Using Content Types to Specify XML Document Properties
This is the second in a five-part series on how to use the built-in XML parser in WSS V3 to promote and demote document properties in your XML files, including InfoPath 2007 forms.
When WSS V3 invokes the built-in XML parser to parse XML files, the parser uses the document's content type to determine which document properties map to which content type columns, and where those document properties are stored in the document itself. Therefore, to have WSS V3 use the built-in XML parser with your XML files, you must:
· Create a content type that includes the necessary parsing information. For each document property you want promoted and demoted, include a field definition that includes the name of the document property that maps to the column the field definition represents, and where the document property is stored in the document.
· Make sure that the content type ID is a document property that is demoted into the document itself. This ensures that the built-in XML parser can identify and access the correct content type for the document. (We’ll talk about this more in a later post.)
Content Type Information for XML Parsing
Document properties are promoted to and demoted from columns on the document library in which the document is stored. If the document is assigned a content type, these columns are specified in the content type definition. In the content type definition XML, each column included in the content type is represented by a FieldRef element.
Note Field elements represent columns that are defined for a site or list. FieldRef elements represent references to columns that are included in the content type. The FieldRef element contains column attributes that you can override for the column as it appears in this specific content type, such as the display name of the column, and whether it is hidden, or required on the content type. This information also includes the location of the document property to map to this column as it appears in the content type. This enables you to specify different locations for the document property that maps to the column in different content types.
Because of this, to specify the information the built-in XML parser needs to promote and demote a document property, you must edit the FieldRef element that represents the document property's corresponding column in the content type definition.
The figure below illustrations the actions the parser takes when an XML file is checked in to a document library. WSS V3 invokes the parser, which looks at the content type ID column to determine where in the document the document's content type ID is stored. The parser then looks inside the document for its content type at this location. The parser then examines the content type, to determine which FieldRef elements contain document property information. For each FieldRef element mapped to a document property, the parser looks for the document property at the location in the document specified in the matching FieldRef element. If the parser finds the document property at the specified location, it promotes that value to the matching column.
When an XML document is first uploaded to a document library, the built-in XML parser must first determine the content type of the document, and whether that content type is associated with the document library.
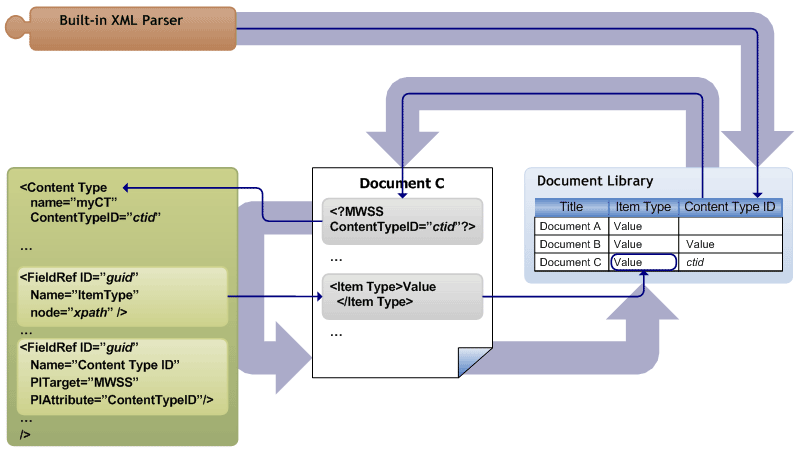
There are several attributes you can edit in a Field or FieldRef element to map that element to a document property and specify the location of the property in the document.
First, the Field or FieldRef element must contain an ID attribute that specifies the ID of the column in the document library. For example:
<FieldRef
ID="{4B1BF6C6-4F39-45ac-ACD5-16FE7A214E5E}"
Name="EmployeeID”/>
Next, add additional attributes to the Field or FieldRef element that specifies the location of the document property in the document. Document properties can be stored in either:
· The XML content of the document, or
· The processing instructions of the document.
The attributes you add to the Field or FieldRef element to specify the property location depends on whether the property is stored as XML content or processing instructions. These attributes are mutually exclusive; if you add an attribute that specifies a location in the XML content, you cannot also add attributes that specify a location in the processing instructions.
To edit a column’s field definition schema programmatically, use the SPField.SchemaXML object.
Specifying Properties in Document XML Content
If you store the document property in the document as XML content, you specify an XPath expression that represents the location of the property within the document. Add a Node attribute to the Field or FieldRef element, and set it equal to the XPath expression. For example:
<FieldRef
ID="{4B1BF6C6-4F39-45ac-ACD5-16FE7A214E5E}"
Name="EmployeeID"
node="/my:myFields/my:employee"/>
Document Property Value Collections
If you specify an XPath expression that returns a collection of values, you can also include an aggregation attribute in the Field or FieldRef element. The aggregation attribute specifies the action to take on the value set returned. This action can be either an aggregation function, or an indication of the particular element within the collection.
Possible values include the following:
· sum
· count
· average
· min
· max
· merge
· plaintext Converts node text content into plain text.
· first Specifies that property promotion and demotion be applied to the first element in the collection.
· last Specifies that property promotion and demotion be applied to the last element in the collection.
For example:
<FieldRef
ID="{4B1BF6C6-4F39-45ac-ACD5-16FE7A214E5E}"
Name="TotalToExpense”
node="/my:myFields/my:expense"
aggregation="sum"/>
Specifying Properties in Document Processing Instructions
Because processing instructions need not be just XML, XPath expressions are insufficient to identify document properties stored in processing instructions. Instead, you must add a pair of attributes to the Field or FieldRef element that specify the processing instruction and processing instruction attribute you want to use as a document property:
· Add a PITarget attribute to specify the processing instruction in which the document property is stored in the document.
· Add a PIAttribute attribute to specify the attribute to use as the document property.
For example:
<FieldRef
ID="{4B1BF6C6-4F39-45ac-ACD5-16FE7A214E5E}"
Name="columnName"
PITarget="mydocumenttype"
PIAttribute="propertyAttribute"/>
These attributes would instruct the parser to examine the following processing instruction and attribute for the document property value:
<?mydocumenttype propertyAttribute="value"?>
You can also add another pair of attributes, PrimaryPITarget and PrimaryPIAttribute. This attribute pair is optional. Like PITarget and PIAttribute, they work in unison to identify the location of the document property. However, if they are present, the built-in XML parser looks for the document property in the location they specify first. If there is a value at that location, the parser uses that value and ignores the PITarget and PIAttribute attributes. Only if the location specified by the PrimaryPITarget and PrimaryPIAttribute attributes returns a null value does the parser then look for the document property at the location specified by the PITarget and PIAttribute attribute pair.
If you specify the PrimaryPITarget and PrimaryPIAttribute attributes, you must also specify PITarget and PIAttribute attributes. The parser only uses the PrimaryPITarget and PrimaryPIAttribute attributes if the processing instruction attribute specified by the PITarget and PIAttribute pair does not exist in the document, not if that attribute exists but is null or empty.
In my next post, we’ll discuss how the XML parser determines a document’s content type in the first place.