Parallel partition processing available for Tabular Models in SQL Server 2016 Preview
One of the great new features that was actually added back in CTP 2.0 of SQL Server 2016 Preview is the ability to process partitions in a table in parallel for Tabular Models. Today I want to highlight this highly requested feature and show you what this might mean for your Tabular models.
With parallel partition processing, the partitions of a single table will now be processed in parallel instead of sequentially, as is the case prior to SQL Server 2016.
Partitions are used to manage data in a table. For example, a single sales table can be divided into partitions by month. Let’s say you have 2 years of data. When you create a partition by month, you split your table into 24 partitions. This now enables you to refresh each individual partition if necessary. You can refresh just the partition for the current month to load the most recent data, so you don’t have to refresh all the data. But often, data in the past changes as well. In this case, all the data in the table needs to be refreshed periodically (several times a day or once a night) to make sure all the data remains current.
With parallel partition processing, each defined partition can be processed in parallel. This means that two expensive operations per partition, that is loading the data from the data source and compressing the data into VertiPaq, are parallelized. This will of course put more load onto your data source and your SSAS server but will reduce the processing time significantly.
Let’s take a quick look at what this means. In my example, I split up a table with 220 million rows into six partitions as shown in the following screenshot.
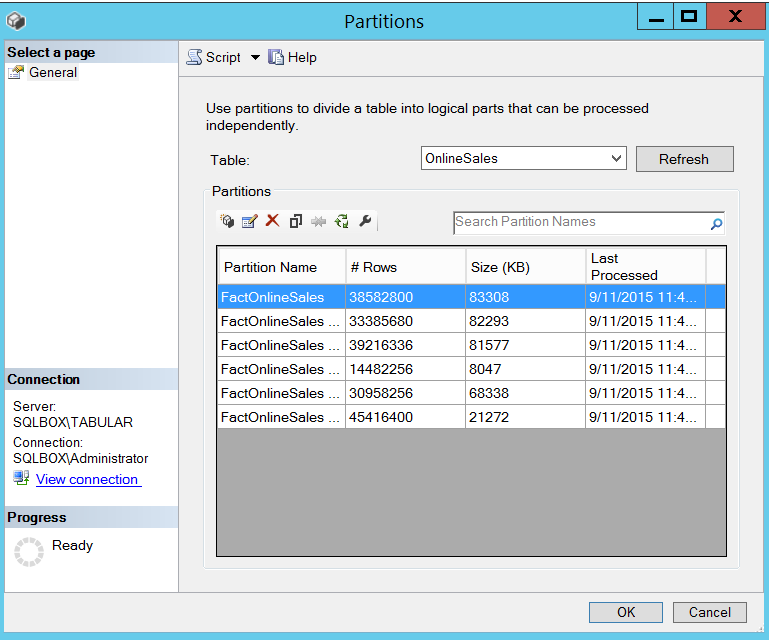
Now when I process these partitions sequentially, loading all the data takes 13 minutes and 44 seconds. You can see the duration in the bottom-right corner of the query window.
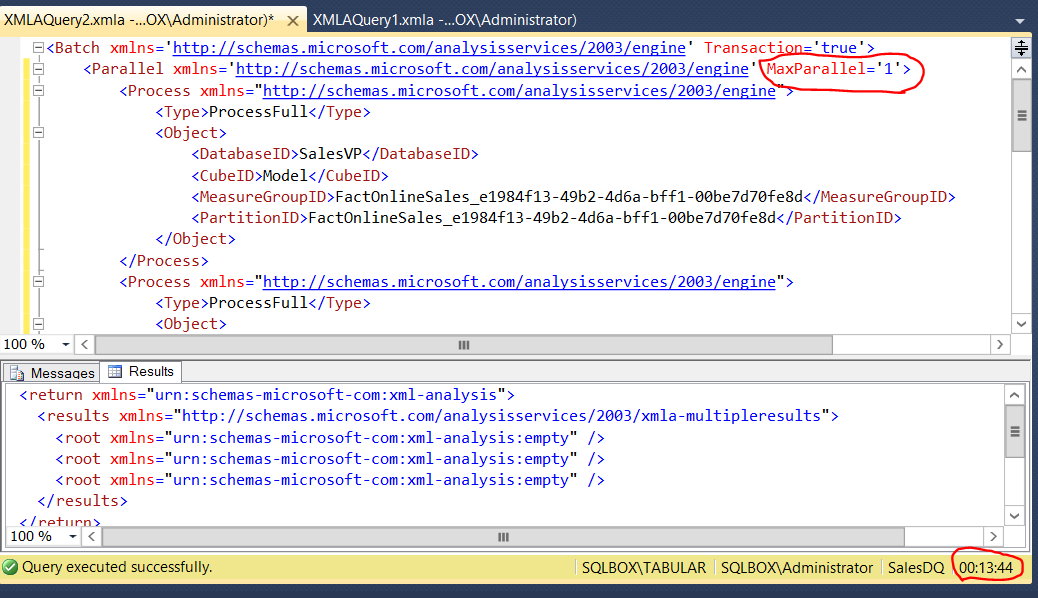
I used a Batch command so that I could insert a Parallel command with the MaxParallel parameter set to 1, meaning the same as sequentially.
On the other hand, simply refreshing the table in SQL Server 2016 automatically refreshes the partitions in parallel. Loading all the data now takes 7 minutes and 17 seconds.
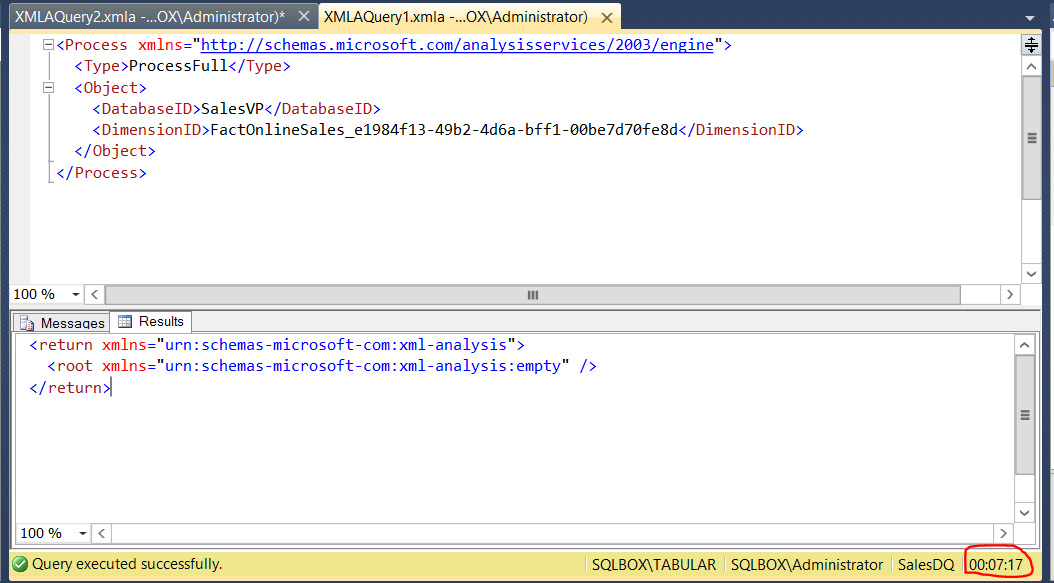
That is a pretty good improvement, especially considering the fact that SSAS is running locally together with the SQL Server database engine on my test computer. The performance improvement will be even more significant with decent SQL Server and SSAS hardware, especially when both engines run on different computers.
So how can you use this new feature? You can simple restore an existing model to a SQL Server 2016 Preview instance of Analysis Services and process your table! As mentioned before, Analysis Services will automatically process all partitions in parallel. You don’t need to do anything else, although it doesn’t hurt to review your current partitioning schemes just to make sure that you are indeed getting the most out of this exciting processing capability. Tabular models are getting better and better. Stay tuned for more articles covering Tabular improvements coming soon.