Determine Availability Group Synchronization State, Minimize Data Loss When Quorum is Forced
When Windows Cluster quorum is lost either due to a short term network issue, or a disaster causes long term down time for the server that hosted your primary replica, and forcing quorum is required in order to quickly bring your availability group resource online, a number of circumstances should be considered to eliminate or reduce data loss.
The following scenarios are discussed in order beginning with best-case scenario for minimizing data loss, in the event that quorum must be forced, given these different circumstances:
- The availability of the original primary replica
- The replica availability mode (synchronous or asynchronous)
- The synchronization state of the secondary replicas (SYNCHRONIZED, SYNCHRONIZING, NOT_SYNCHRONIZED)
- The number of secondary replicas available for failover
IMPORTANT When you must force quorum to restore your Windows cluster and availability groups to productivity, your SQL Server availability groups will NOT transition back to their original PRIMARY and SECONDARY roles. After you have restarted the Cluster service using forced quorum on any recoverable replicas, availability groups transition to the RESOLVING state, and require an additional failover command to bring back into the PRIMARY and SECONDARY roles by executing the following command on the SQL Server instance where you intend to bring the availability group back online in the primary role:
ALTER AVAILABILITY GROUP agname FORCE_FAILOVER_ALLOW_DATA_LOSS
This is by design - forcing quorum is an administrative override and no assumption will be made about where the primary replica should come online.
Scenario - Quorum was lost, my primary replica is still available - failover to original primary
If at all possible, recover the server hosting the original primary replica, if it is available. This guarantees no data loss. If quorum is lost due to a network or some other issue, that leaves the server that was hosting the original primary replica intact, force quorum (if Cluster does not or cannot recover on its own) on the server hosting the original primary replica.
At this stage Windows Cluster will be running, but your availability group will still be reported as RESOLVING and no availability databases will be accessible. Despite being the original primary, you still must failover the availability group, and the only syntax supported after forcing of quorum is:
ALTER AVAILABILITY GROUP agname FORCE_FAILOVER_ALLOW_DATA_LOSS
This step is necessary for the availability group to transition to the primary role. Rest assured, despite the fact that you are issuing the command '...FORCE_FAILOVER_ALLOW_DATA_LOSS' so long as this was the primary, no data loss is incurred.
Scenario - I have lost my primary - failover to a synchronous secondary that is SYNCHRONIZED
When a disaster occurs which results in the long term or permanent loss of your primary replica, to avoid data loss, fail over to a secondary replica 1) whose availability mode is synchronous and 2) is in the SYNCHRONIZED state. So long as the replica was in a SYNCHRONIZED state or your key databases were in a SYNCHRONIZED state at the time that quorum was lost, you can failover to this replica and be assured of no data loss.
In order to determine if your synchronous secondary is in a SYNCHRONIZED state
Force quorum to start the Cluster service on a server that hosted a secondary replica configured for synchronous commit.
Connect to SQL Server and query sys.dm_hadr_database_replica_cluster_states.is_failover_ready. The DMV returns a row for each database in each availability group replica. Here is a sample query that returns each availability database name and its failover ready state at each replica. This query reports the IS_FAILOVER_READY state of each availability database at each replica, ie, if those databases at each replica are in a SYNCHRONIZED state. For example, you force quorum on and connect to SQL Server on SQLNODE2 which is a synchronous commit secondary replica. The query reports several key databases are not failover ready on SQLNODE2, but the same query results also report that the same databases are synchronized on SQLNODE3.
select arc.replica_server_name, drc.is_failover_ready, drc.database_name
from sys.dm_hadr_database_replica_cluster_states drc
join sys.dm_hadr_availability_replica_cluster_states arc
on(drc.replica_id = arc.replica_id) --where arc.replica_server_name = @@servername
IMPORTANT: Do this step before you failover your availability group
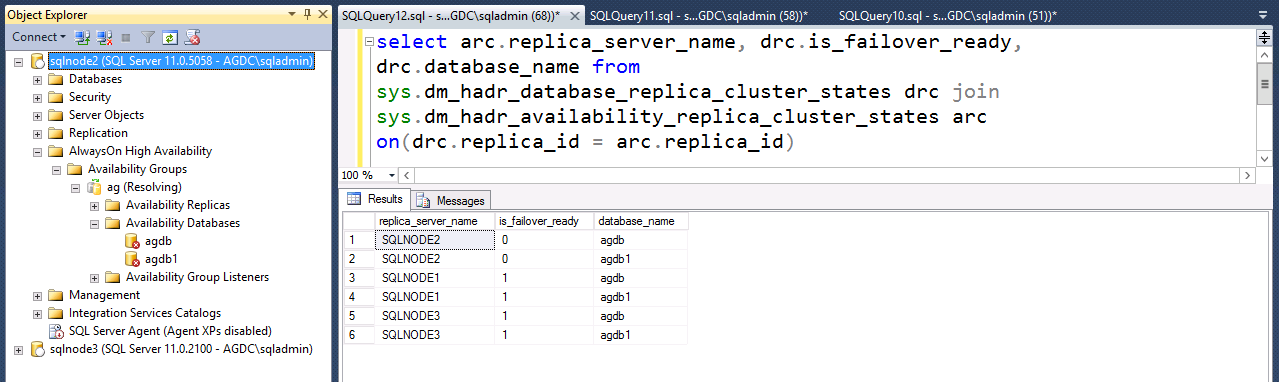
This may lead you to shut down Cluster on SQLNODE2 and force quorum on SQLNODE3, where you can issue the ALTER AVAILABILITY GROUP...FORCE_FAILOVER_ALLOW_DATA_LOSS command to bring the availability databases into the primary role.
Scenario - I have lost my primary - minimize data loss on failover to SYNCHRONIZING or NOT_SYNCHRONIZED secondary replica
If quorum has been lost and the primary is not available, in the event that you must consider failover to a synchronous commit replica that is not failover ready (sys.dm_hadr_database_replica_cluster_states.is_failover_ready= 0), or an asynchronous commit replica, there are further steps that can be taken to minimize data loss in the event that you have more than one secondary replica to choose from.
Choose secondary to failover by comparing database hardened LSN in SQL Server Error Log (SQL Server 2014 only)
In SQL Server 2014, the last hardened LSN information is reported in the SQL Server error log when an availability replica transitions to the RESOLVING role. Open the SQL Server error log and locate where each key availability database transitions from SECONDARY to RESOLVING. Immediately following is additional logged information - the key comparator is the 'Hardened Lsn.'
For example, here we check the following SQL Error Log entries from our two secondaries - SQLNODE2 and SQLNODE3 as they transition to RESOLVING:
SQLNODE2
2014-11-25 12:39:32.43 spid68s The availability group database "agdb" is changing roles from "SECONDARY" to "RESOLVING" because the mirroring session or availability group failed over due to role synchronization. This is an informational message only. No user action is required.
2014-11-25 12:39:32.43 spid68s State information for database 'agdb' - Hardended Lsn: '(77:5368:1)' Commit LSN: '(76:17176:3)' Commit Time: 'Nov 25 2014 12:39PM'
Let's also review the same information in the SQL Server error log on secondary SQLNODE3:
SQLNODE3
2014-11-25 12:39:32.52 spid51s The availability group database "agdb" is changing roles from "SECONDARY" to "RESOLVING" because the mirroring session or availability group failed over due to role synchronization. This is an informational message only. No user action is required.
2014-11-25 12:39:32.52 spid51s State information for database 'agdb' - Hardended Lsn: '(72:1600:1)' Commit LSN: '(72:1192:3)' Commit Time: 'Nov 25 2014 12:39PM'
SQLNODE2 has a more advanced hardened LSN. Failing over to SQLNODE2 will minimize data loss.
Choose secondary to failover by failing over each secondary then querying sys.dm_hadr_database_replica_states.last_hardened_lsn (SQL Server 2012)
WARNING The following steps suggest forcing quorum on separate Cluster nodes, to determine the progress of log replication to the availability group replica. Prior to performing these steps configure the Cluster services on each available node to Manual startup, otherwise, you run the risk of creating more than one quorum node set; that is a split-brain scenario. Ensure that whenever forcing quorum ensure that no other node is currently running with a forced quorum - this can result in a split-brain scenario.
Since SQL Server 2012 does not report the last_hardened_lsn in the SQL Server error log when transitioning to RESOLVING, you can examine the last hardened LSN on each secondary by forcing quorum and failing over the availability group on one secondary and then the other secondary, each time querying sys.dm_hadr_database_replica_states.last_hardened_lsn. Consider the example, with SQLNODE2 and SQLNODE3 secondary replicas:
1 Force quorum on SQLNODE2.
2 Connect to the local instance of SQL Server on SQLNODE2 and force failover of the availability group:
ALTER AVAILABILITY GROUP agname FORCE_FAILOVER_ALLOW_DATA_LOSS
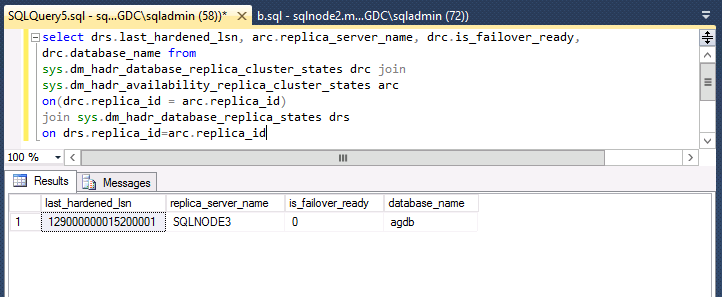
3 Query for the last_hardened_lsn of your availability databases:
select drs.last_hardened_lsn, arc.replica_server_name, drc.is_failover_ready,
drc.database_name from
sys.dm_hadr_database_replica_cluster_states drc join
sys.dm_hadr_availability_replica_cluster_states arc
on(drc.replica_id = arc.replica_id)
join sys.dm_hadr_database_replica_states drs
on drs.replica_id=arc.replica_id
4 Stop the Cluster service on SQLNODE2.
5 Force quorum on SQLNODE3.
6 Connect to the local instance of SQL Server on SQLNODE3 and force failover of the availability group:
ALTER AVAILABILITY GROUP agname FORCE_FAILOVER_ALLOW_DATA_LOSS
7 Use the same query in step 3 above, to query last_hardened_lsn for your availability databases and compare those values to the results querying SQLNODE2.
If SQLNODE3 returned a more advanced last_hardened_lsn, then continue to move towards resuming production with SQLNODE3 hosting the primary replica.
If SQLNODE2 returned a more advanced last_hardened_lsn, stop the Clusters service on SQLNODE3 and then force quorum on SQLNODE2. Failover the availability group to bring the primary replica online in SQLNODE2.
When connectivity is restored between the nodes of the Cluster, the remaining replicas will transition back to the SECONDARY role and their availability databases will be in a SUSPENDED state.
Finally, an alternative is to drop the availability group on each secondary and RESTORE AGDB WITH RECOVERY - this will recover the database and then you can individually inspect the databases at each node to confirm the databases with the most changes. This may require knowledge of key tables whose timestamp columns can be queried. Then, you can recreate the availability group with a single primary replica and add your listener.