IaaS with SQL AlwaysOn - Tuning Failover Cluster Network Thresholds
Symptom
When running Windows Failover Cluster nodes in IaaS with SQL Server AlwaysOn, changing the cluster setting to a more relaxed monitoring state is recommended. Cluster settings out of the box are restrictive and could cause unneeded outages. The default settings are designed for highly tuned on premises networks and does not take into account the possibility of induced latency caused by a multi-tenant environment such as Windows Azure (IaaS).
Windows Server Failover Clustering is constantly monitoring the network connections and health of the nodes in a Windows Cluster. If a node is not reachable over the network, then recovery action is taken to recover and bring applications and services online on another node in the cluster. Latency in communication between cluster nodes can lead to the following error:
Error 1135 (system event log)
Cluster node 'Node1' was removed from the active failover cluster membership. The Cluster service on this node may have stopped. This could also be due to the node having lost communication with other active nodes in the failover cluster. Run the Validate a Configuration wizard to check your network configuration. If the condition persists, check for hardware or software errors related to the network adapters on this node. Also check for failures in any other network components to which the node is connected such as hubs, switches, or bridges.
Cluster.log Example
0000ab34.00004e64::2014/06/10-07:54:34.099 DBG [NETFTAPI] Signaled NetftRemoteUnreachable event, local address 10.xx.x.xxx:3343 remote address 10.x.xx.xx:3343
0000ab34.00004b38::2014/06/10-07:54:34.099 INFO [IM] got event: Remote endpoint 10.xx.xx.xxx:~3343~ unreachable from 10.xx.x.xx:~3343~
0000ab34.00004b38::2014/06/10-07:54:34.099 INFO [IM] Marking Route from 10.xxx.xxx.xxxx:~3343~ to 10.xxx.xx.xxxx:~3343~ as down
0000ab34.00004b38::2014/06/10-07:54:34.099 INFO [NDP] Checking to see if all routes for route (virtual) local fexx::xxx:5dxx:xxxx:3xxx:~0~ to remote xxx::cxxx:xxxd:xxx:dxxx:~0~ are down
0000ab34.00004b38::2014/06/10-07:54:34.099 INFO [NDP] All routes for route (virtual) local fxxx::xxxx:5xxx:xxxx:3xxx:~0~ to remote fexx::xxxx:xxxx:xxxx:xxxx:~0~ are down
0000ab34.00007328::2014/06/10-07:54:34.099 INFO [CORE] Node 8: executing node 12 failed handlers on a dedicated thread
0000ab34.00007328::2014/06/10-07:54:34.099 INFO [NODE] Node 8: Cleaning up connections for n12.
0000ab34.00007328::2014/06/10-07:54:34.099 INFO [Nodename] Clearing 0 unsent and 15 unacknowledged messages.
0000ab34.00007328::2014/06/10-07:54:34.099 INFO [NODE] Node 8: n12 node object is closing its connections
0000ab34.00008b68::2014/06/10-07:54:34.099 INFO [DCM] HandleNetftRemoteRouteChange
0000ab34.00004b38::2014/06/10-07:54:34.099 INFO [IM] Route history 1: Old: 05.936, Message: Response, Route sequence: 150415, Received sequence: 150415, Heartbeats counter/threshold: 5/5, Error: Success, NtStatus: 0 Timestamp: 2014/06/10-07:54:28.000, Ticks since last sending: 4
0000ab34.00007328::2014/06/10-07:54:34.099 INFO [NODE] Node 8: closing n12 node object channels
0000ab34.00004b38::2014/06/10-07:54:34.099 INFO [IM] Route history 2: Old: 06.434, Message: Request, Route sequence: 150414, Received sequence: 150402, Heartbeats counter/threshold: 5/5, Error: Success, NtStatus: 0 Timestamp: 2014/06/10-07:54:27.665, Ticks since last sending: 36
0000ab34.0000a8ac::2014/06/10-07:54:34.099 INFO [DCM] HandleRequest: dcm/netftRouteChange
0000ab34.00004b38::2014/06/10-07:54:34.099 INFO [IM] Route history 3: Old: 06.934, Message: Response, Route sequence: 150414, Received sequence: 150414, Heartbeats counter/threshold: 5/5, Error: Success, NtStatus: 0 Timestamp: 2014/06/10-07:54:27.165, Ticks since last sending: 4
0000ab34.00004b38::2014/06/10-07:54:34.099 INFO [IM] Route history 4: Old: 07.434, Message: Request, Route sequence: 150413, Received sequence: 150401, Heartbeats counter/threshold: 5/5, Error: Success, NtStatus: 0 Timestamp: 2014/06/10-07:54:26.664, Ticks since last sending: 36
……
……
0000ab34.00007328::2014/06/10-07:54:34.100 INFO <realLocal>10.xxx.xx.xxx:~3343~</realLocal>
0000ab34.00007328::2014/06/10-07:54:34.100 INFO <realRemote>10.xxx.xx.xxx:~3343~</realRemote>
0000ab34.00007328::2014/06/10-07:54:34.100 INFO <virtualLocal>fexx::xxxx:xxxx:xxxx:xxxx:~0~</virtualLocal>
0000ab34.00007328::2014/06/10-07:54:34.100 INFO <virtualRemote>fexx::xxxx:xxxx:xxxx:xxxx:~0~</virtualRemote>
0000ab34.00007328::2014/06/10-07:54:34.100 INFO <Delay>1000</Delay>
0000ab34.00007328::2014/06/10-07:54:34.100 INFO <Threshold>5</Threshold>
0000ab34.00007328::2014/06/10-07:54:34.100 INFO <Priority>140481</Priority>
0000ab34.00007328::2014/06/10-07:54:34.100 INFO <Attributes>2147483649</Attributes>
0000ab34.00007328::2014/06/10-07:54:34.100 INFO </struct mscs::FaultTolerantRoute>
0000ab34.00007328::2014/06/10-07:54:34.100 INFO removed
……
……
0000ab34.0000a7c0::2014/06/10-07:54:38.433 ERR [QUORUM] Node 8: Lost quorum (3 4 5 6 7 8)
0000ab34.0000a7c0::2014/06/10-07:54:38.433 ERR [QUORUM] Node 8: goingAway: 0, core.IsServiceShutdown: 0
0000ab34.0000a7c0::2014/06/10-07:54:38.433 ERR lost quorum (status = 5925)
Cause
There are 2 settings that are used to configure the connectivity health of the cluster.
Delay – This defines the frequency at which cluster heartbeats are sent between nodes. The delay is the number of seconds before the next heartbeat is sent. Within the same cluster there can be different delays between nodes on the same subnet and between nodes which are on different subnets.
Threshold – This defines the number of heartbeats which are missed before the cluster takes recovery action. The threshold is a number of heartbeats. Within the same cluster there can be different thresholds between nodes on the same subnet and between nodes which are on different subnets.
By default Windows Server 2016 sets the SameSubnetThreshold to 10 and SameSubnetDelay to 1000 ms. For example, if connectivity monitoring fails for 10 seconds, the failover Threshold is reached resulting in the unreachable node being removed from cluster membership. This results in the resources being moved to another available node on the cluster. Cluster errors will be reported, including cluster error 1135 (above) is reported.
Resolution
In an IaaS environment, relax the Cluster network configuration settings.
Steps to verify current configuration
Check the current Cluster network configuration settings use the get-cluster command:
PS C:\Windows\system32> get-cluster | fl *subnet*
Default, minimum, maximum, and recommended values for each support OS
| OS | Min | Max | Default | Recommended | |
| CrossSubnet Threshold | 2008 R2 | 3 | 20 | 5 | 20 |
| CrossSubnet Threshold | 2012 | 3 | 120 | 5 | 20 |
| CrossSubnet Threshold | 2012 R2 | 3 | 120 | 5 | 20 |
| CrossSubnet Threshold | 2016 | 3 | 120 | 20 | 20 |
| SameSubnet Threshold | 2008 R2 | 3 | 10 | 5 | 10 |
| SameSubnet Threshold | 2012 | 3 | 120 | 5 | 10 |
| SameSubnet Threshold | 2012 R2 | 3 | 120 | 5 | 10 |
| SameSubnetThreshold | 2016 | 3 | 120 | 10 | 10 |
The values for Threshold reflect the current recommendations, for on premise clusters as explained in the following article:
Fine tuning failover cluster network thresholds in Windows Server 2012 R2
The Threshold defines the number of heartbeats which are missed before the cluster takes recovery action. The threshold is a number of heartbeats. Within the same cluster there can be different thresholds between nodes on the same subnet and between nodes which are on different subnets.
Recommendations for changing to more relaxed settings for multi-tenant environments like Azure (IaaS)
Note Increasing the resiliency of your Cluster environment by adjusting the Cluster network configuration settings can result in increased downtime. For more details and guidance on the modification of Windows Cluster network configuration settings, see the following article:
Tuning Failover Cluster Network Thresholds
1 Modify to more relaxed settings
NOTE The following changes to the Cluster thresholds are in effect immediately and do not require restart of Cluster or of any resources.
The following settings are recommended for both same subnet and cross-region deployments of AlwaysOn availability groups.
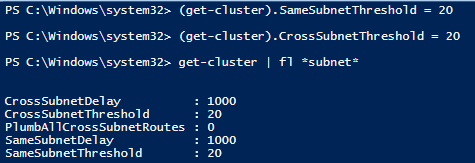
PS C:\Windows\system32> (get-cluster).SameSubnetThreshold = 20
PS C:\Windows\system32> (get-cluster).CrossSubnetThreshold = 20
2 Verify the changes
PS C:\Windows\system32> get-cluster | fl *subnet*
References
For more information on tuning Windows Cluster network configuration settings see:
Tuning Failover Cluster Network Thresholds
https://blogs.msdn.com/b/clustering/archive/2012/11/21/10370765.aspx
For information on using cluster.exe to tune Windows Cluster network configuration settings see:
How to Configure Cluster Networks for a Failover Cluster
https://technet.microsoft.com/en-us/library/bb690953(v=EXCHG.80).aspx