Using SqlDataReader’s new async methods in .Net 4.5
With .Net 4.5, ADO.NET introduced two asynchronous methods to the SqlDataReader class: ReadAsync and NextResultAsync. These two methods allow you to move to the next row or result set asynchronously and represent a much more fine-grained level of asynchronous access to data compared to .Net 4.0 (which only had asynchronous command execution). However, for the .Net 4.5 we have gone a step further and introduced two new column-level asynchronous methods: IsDBNullAsync and GetFieldValueAsync<T>.
Flow of Data
To understand the need for different levels of asynchronous methods, we need to have a look at how SQL Server sends data to clients like ADO.NET.
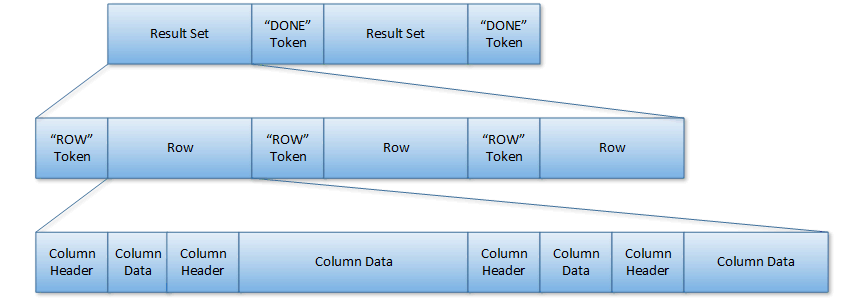
Figure 1 - Row data sent from SQL Server via the TDS protocol |
SQL Server sends data to the client using the Tabular Data Stream (TDS) protocol which, as shown in the diagram above, separates each result set with a “DONE” token, each row with a “ROW” token and each column has both a header and actual data (note that this is a simplification of TDS useful for understanding ADO.NET, if you want to learn more about TDS you can get the full specification on the MSDN). So, when you call NextResult, ADO.NET reads the rest of the current result set and the “DONE” token afterwards, and then returns true if there is more data available. Similarly, calling Read will read off the rest of the current row and the next “ROW” token and getting the value for a column will cause the data for any preceding column to also be read. For getting column values there is also multiple behaviors for what to do with the previous columns’ data: in “Default” mode (also called “non-sequential” mode) the previous columns’ data is stored and you can go back and re-read that column from SqlDataReader’s data storage; whereas in “SequentialAccess” mode the data for the previous columns is discarded and you will get an exception if you try to re-read it.
For the new asynchronous methods in .Net 4.5, their behavior is exactly the same as with the synchronous methods, except for one notable exception: ReadAsync in non-sequential mode. The difference is that ReadAsync will not just read up to the “ROW” token of the current row, but will also read and parse all of the column data for that row as well. By doing this, ADO.NET only pays the overhead to call into its parsing code once per row, instead of paying it every time a new column is read.
Asynchronous column access
An important guidance for writing asynchronous APIs is to ensure that asynchronous methods do large or “chunky” operations, which doesn’t seem to mesh well with column-level asynchronous access until you look closely at how they work. Consider a table that has a varchar column with about 2000 characters per row. This means that you can fit about four of these columns per packet (assuming that you are using the default packet size, and ignoring any headers or other overhead). If you are reading the row via the Read method, or you are in sequential mode, then getting the column synchronously will block the thread for every fifth row. For an application or web server, having every fifth row block a thread can end up becoming a serious scalability issue. The same issue can occur if you are ignoring this 2000 character column, but checking if the next column in the row is null: IsDBNull needs to read the header for the target column, which means that it will need to read past any previous columns (such as our 2000 character column). This can become even worse if you have a column that is megabytes, or even gigabytes, in size, since you will be typically using sequential mode, and you can partially read such a column (using methods like GetStream), which means that IsDBNull will need to read off the rest of the row synchronously.
When to use what
The new asynchronous methods that SqlDataReader exposes make it very easy to create a scalable application, but they only provide a benefit if their synchronous counterpart would have blocked a thread, and that only happens if ADO.NET requires more data from the network.
So to choose whether or not to call an asynchronous method, you need to consider how much data the method is likely to use and therefore if it is likely to require a new network packet. You can calculate the probability of needing a new packet by comparing the size of the data you are reading with the maximum packet size, or you can use the following guidelines:
Default (non-sequential) mode vs SequentialAccess – It is important to decide before you create a SqlDataReader whether you want to use non-sequential or sequential access mode. In most cases using the Default (non-sequential) access mode is the better choice, as it allows an easier programming model (you can access any column in any order) and you will get better performance using ReadAsync. However, since non-sequential access mode has to store the data for the entire row, it can cause issues if you are reading a large column from the server (such as varbinary(MAX), varchar(MAX), nvarchar(MAX) or XML). In this case using sequential access mode will allow you to stream these large columns rather than having to buffer the entire column into memory.
NextResult vs. NextResultAsync – Whenever possible, you should be using NextResultAsync() to move between result sets. This will allow leftover rows in the old result set to be read off asynchronously, as well as other TDS tokens (which were excluded from figure 1 for simplicity) which can sit between result sets.
Read vs ReadAsync – It is also a good idea to call ReadAsync: in non-sequential mode this will read in all column data, which can potential span multiple packets, allowing faster access to the column values. In sequential mode ADO.NET will need to finish reading the data for the current row (if it hasn’t been read entirely), and there is the potential for some TDS tokens to sit between rows which can then be read asynchronously.
IsDBNull and GetFieldValue<T> vs IsDBNullAsync and GetFieldValueAsync<T> - If you had previously called ReadAsync and are using non-sequential access, then calling the synchronous versions of these methods will provide the best performance since the column data has already been read and processed (so calling the asynchronous method just adds the overhead of wrapping the value in a Task). However, if you called Read in non-sequential access mode, or if you are using sequential access mode, then the decision is much harder as you need to consider how much data you need to read to get to your desired column and how much data that column may contain. If you’ve read the previous column, and the target column is small (like a Boolean, a DateTime or a numeric type) then you may want to consider using a synchronous method. Alternatively, if the target column is large (like a varbinary(8000)) or you need to read past large columns, then using an asynchronous method is much better. Finally, if the target column is massive (like a varbinary(MAX), varchar(MAX), nvarchar(MAX) or XML) then you should consider the new GetStream, GetTextReader or GetXmlReader methods instead.
Test early, test often
Finally, please be aware that the recommendations above are based on the workings of ADO.NET and what we have observed in our tests. You need to consider what type of data your application is using to see at what level (result set, row or column) it makes sense to call asynchronous methods. The best way to check this is to build up a suite of performance and scalability tests such that you can accurately measure and tune your application.
And the best way to do this is with the Visual Studio 2012 and .Net 4.5.
Happy Coding!
Daniel Paoliello
Software Development Engineer
ADO.NET Managed Providers and DataSet Team